-

أسرع طرق فقدان الوزن: الحل السحري أم الجهد المستمر؟
•
“اسرع طريقة لفقدان الوزن” هو موضوع شائك ومثير للاهتمام في عصرنا الحالي، حيث يسعى الكثير من الأشخاص للعثور على حل سحري يجعلهم يفقدون الوزن بشكل سريع وفعال….
-

كيف تختار أفضل طريقة لانزال الوزن بنجاح؟
•
أفضل طريقة لانزال الوزن إذا كنت تبحث عن أفضل طريقة لانزال الوزن بنجاح، فإنك في المكان الصحيح. يعد فقدان الوزن والحفاظ على وزن صحي ومثالي من أهم الأهداف الت…
-

أهمية النظام الغذائي الصحي لصحة الجسم والعقل
•
ماهو النظام الغذائي الصحي؟ إن النظام الغذائي الصحي يعد أحد العوامل الأساسية في الحفاظ على صحة الجسم والعقل. فمن خلال تناول الطعام الصحي والمتوازن يمكن تعز…
-

أهمية اتباع نظام الغذاء الصحي للحفاظ على الصحة
•
نظام الغذاء الصحي هو الأساس الأساسي للحفاظ على الصحة والعافية. إن تناول الطعام الصحي والمتوازن يساعد في تعزيز جهاز المناعة والوقاية من الأمراض المزمنة مثل…
-

فوائد اتباع نظام غذائي للتخسيس وتحقيق الهدف المثالي
•
فوائد اتباع نظام غذائي للتخسيس يعد اتباع نظام غذائي للتخسيس أمراً مهماً للكثير من الناس الذين يسعون لتحقيق وزنهم المثالي والحفاظ على صحتهم العامة. فقد أثب…
-

كيفية اتباع نظام غذائي صحي لانقاص الوزن بفعالية
•
كيفية اتباع نظام غذائي صحي لانقاص الوزن تعتبر فقدان الوزن والحفاظ على صحة جيدة من أهم الأهداف التي يسعى إليها الكثيرون. ومن أجل تحقيق ذلك، يعتبر اتباع نظام…
-

أهمية العناصر الغذائية في الحفاظ على صحة الجسم والعقل
•
العناصر الغذائية هي المواد التي يحتاجها الجسم للحفاظ على صحته ونموه وإنتاج الطاقة اللازمة لأداء الأنشطة اليومية. تلعب العناصر الغذائية دوراً كبيراً في الحف…
-

اتباع نظام غذائي لزيادة الوزن: الخطوات الفعّالة لزيادة الكتلة الجسدية
•
اتباع نظام غذائي لزيادة الوزن يعد أمرًا مهمًا للأشخاص الذين يعانون من نقص في الوزن ويرغبون في زيادة كتلتهم الجسدية وتحسين حالتهم الصحية بشكل عام. فإذا كنت…
-

تحسين النظام الصحي: تطوير وتحسين الخدمات الطبية للمواطنين
•
نظام صحي، هو أحد العناصر الأساسية في حياة الإنسان، حيث يهدف إلى توفير الرعاية الصحية والخدمات الطبية الضرورية للمواطنين. ولذلك، يعتبر تحسين النظام الصحي وت…
-

أهمية العناية بالصحة وأثرها الإيجابي على الحياة اليومية
•
تعتبر العناية بالصحة من العوامل الأساسية التي تؤثر بشكل كبير على جودة الحياة اليومية. فهي تشمل جميع العناصر اللازمة للحفاظ على الجسم والعقل بحالة جيدة، وتض…
-

أهمية الغذاء الصحي لصحة الجسم والعقل
•
إن الغذاء الصحي يعتبر أساسياً لصحة الجسم والعقل، حيث يلعب دوراً هاماً في دعم وتعزيز الصحة العامة والوقاية من الأمراض. فالتغذية السليمة والمتوازنة تمد الجسم…
-

أهمية العناية بالصحة وتأثيرها الإيجابي على الحياة اليومية
•
العناية بالصحة هي أحد أهم العنايات التي يجب أن يوليها الإنسان اهتماماً كبيراً في حياته اليومية. فهي تشمل جميع العادات الصحية والنمط الحياتي الذي يؤثر بشكل…
-

كيفية انقاص الوزن بسرعة وبشكل صحي
•
يعتبر انقاص الوزن بسرعة وبشكل صحي هدفا مهما للكثير من الأشخاص الذين يسعون إلى تحسين صحتهم وشكلهم الخارجي. تحقيق هذا الهدف يتطلب اتباع نظام غذائي ونمط حياة…
-

أهمية اتباع نظام الأكل الصحي لصحة الجسم والعقل
•
نظام الأكل الصحي هو أساس لصحة الجسم والعقل، فهو يلعب دوراً حاسماً في تحسين جودة الحياة والوقاية من الأمراض المزمنة. يعتمد نظام الأكل الصحي على تناول تشكيلة…
-

أهمية اتباع حمية غذائية صحية للحفاظ على الصحة والعافية
•
تعتبر حمية الغذائية من أهم العوامل التي تساهم في الحفاظ على الصحة والعافية. فالتغذية السليمة تلعب دوراً حيوياً في تعزيز صحة الجسم والوقاية من الأمراض المزم…
-

نصائح فعالة لإنقاص الوزن بطرق صحية وآمنة
•
نصائح لإنقاص الوزن إن إنقاص الوزن بطرق صحية وآمنة يعتبر هدفاً مهماً للكثير من الأشخاص الذين يعانون من زيادة الوزن. قد يكون من الصعب التخلص من الدهون الزائ…
-

نصائح الصحة: كيف تحافظ على صحتك بشكل جيد؟
•
نصائح الصحة هي عنصر أساسي في حياتنا اليومية، فهي تساعدنا على الحفاظ على صحتنا بشكل جيد وتجنب الإصابة بالعديد من الأمراض والمشاكل الصحية. بمجرد أن تتبع نصائ…
-

نظام غذائي متوازن لزيادة الوزن: خطوات ونصائح
•
نظام غذائي متوازن لزيادة الوزن: خطوات ونصائح يُعتبر اتباع نظام غذائي متوازن وصحي أمرًا ضروريًا لزيادة الوزن بطريقة صحية وآمنة. فإذا كنت تبحث عن زيادة وزنك…
-

أهمية اتباع نظام غذائي جيد لصحة الجسم
•
نظام غذائي جيد هو أساس الصحة والعافية للجسم. فمن خلال تناول الطعام المتوازن والمغذي يمكننا تحسين وضعنا الصحي والوقاية من الأمراض. إن اتباع نظام غذائي جيد ي…
-

نصائح التغذية الصحية: كيف تحافظ على صحتك وتحقق اللياقة
•
نصائح التغذية الصحية تعتبر أساسية للحفاظ على صحتنا ولتحقيق اللياقة البدنية التي نسعى إليها. فمن خلال اتباع نظام غذائي صحي ومتوازن، يمكننا تعزيز صحتنا وتقوي…
-

زيادة الصحة: الطرق الفعالة لتحسين اللياقة البدنية والتغذية الصحيحة
•
زيادة الصحة: الطرق الفعالة لتحسين اللياقة البدنية والتغذية الصحيحة تعد زيادة الصحة من أهم الأهداف التي يسعى إليها الكثير من الأشخاص في جميع أنحاء العالم….
-

أهمية اتباع نظام غذائي صحي ومتوازن للحفاظ على الصحة
•
اتباع نظام غذائي صحي ومتوازن هو عامل أساسي للحفاظ على الصحة والعافية. إن الاهتمام بتناول الطعام الصحي يساهم في تقوية جهاز المناعة والحفاظ على وظائف الجسم ب…
-

موقع المعلومات: كيفية الوصول إلى المعلومات بفعالية
•
موقع معلومات: كيفية الوصول إلى المعلومات بفعالية إنّ موقع المعلومات أصبح أداة أساسية للحصول على المعلومات بشكل سريع وفعال في عصر تكنولوجيا المعلومات. فبفض…
-

كيف يؤثر نظام غذائي تخسيس على صحتك وشكلك؟
•
يُعتبر نظام غذائي تخسيس من أبرز الوسائل التي يمكن أن تؤثر بشكل كبير على صحتنا وشكلنا. حيث يهدف هذا النوع من النظام الغذائي إلى خسارة الوزن الزائد بطريقة صح…
-

نصائح فعّالة لانقاص الوزن بطرق صحية وآمنة
•
نصائح انقاص الوزن إن انقاص الوزن والحفاظ على وزن صحي يعد تحديًا كبيرًا للكثير من الأشخاص. وبالتالي، فإن البحث عن طرق فعّالة وآمنة لفقدان الوزن يعد من الأم…
-

نصائح وإرشادات لتحسين الصحة النفسية في الحياة اليومية
•
نصائح وإرشادات لتحسين الصحة النفسية في الحياة اليومية تعد الصحة النفسية جزءاً هاماً من الصحة العامة، وتتأثر بالعديد من العوامل اليومية التي قد تؤثر على حا…
-

طرق فعالة لتخسيس الوزن بشكل سريع وصحي
•
طريقة فعالة لتخسيس الوزن هي هدف يسعى اليه الكثيرون في مجتمعنا اليوم، حيث يبحث الكثيرون عن وسائل تساعدهم على فقدان الوزن بشكل سريع وصحي. يتضمن ذلك تحسين نمط…
-

الأطعمة التي تساعد على زيادة الوزن بطريقة صحية
•
الأطعمة التي تساعد على زيادة الوزن بطريقة صحية الاغذية التي تساعد على زيادة الوزن تعتبر الزيادة في الوزن مشكلة تواجه الكثير من الأشخاص، وغالبا ما يكون ال…
-

زيادة الوزن بشكل صحي: الطرق الصحية للزيادة في الوزن
•
زيادة الوزن بشكل صحي هي موضوع يشغل الكثيرين من الأشخاص الذين يعانون من نقص في الوزن ويرغبون في زيادة وزنهم بطرق صحية وآمنة. قد يكون هذا التحدي صعبًا للبعض،…
-

تغذية صحية لزيادة الوزن: كيفية اختيار نظام غذائي مناسب
•
نظام غذائي لزيادة الوزن هو موضوع يثير اهتمام الكثيرين في الوقت الحاضر، حيث يبحث الكثيرون عن طرق صحية وآمنة لزيادة وزنهم وتحسين قوامهم البدني. وفي ظل توفر ا…
-

طرق فعالة لفقدان الوزن بسرعة وبدون جهد
•
طرق فعالة لفقدان الوزن بسرعة وبدون جهد إذا كنت تبحث عن طرق فعالة لفقدان الوزن بسرعة وبدون جهد، فأنت في المكان المناسب. يعتبر فقدان الوزن من المواضيع التي…
-

فوائد الطعام الصحي وأثره على الصحة العامة
•
يعتبر الطعام الصحي أساساً هاماً للحفاظ على صحة الإنسان والوقاية من الأمراض، حيث أن النظام الغذائي السليم يلعب دوراً كبيراً في الحفاظ على صحة الجسم والعقل….
-

نظام غذائي فعّال لتخفيف الوزن بسرعة
•
اريد نظام غذائي لتخفيف الوزن يعتبر البحث عن نظام غذائي فعّال وسريع لتخفيف الوزن أمراً مهماً للكثير من الأشخاص الذين يعانون من مشاكل الوزن الزائد. فالتخلص م…
-

نصائح فعالة لفقدان الوزن بشكل صحي وآمن
•
نصائح لفقدان الوزن يشكل فقدان الوزن بشكل صحي وآمن تحديًا كبيرًا للكثير من الأشخاص، حيث يبحثون عن الطرق الفعالة والمستدامة لتخفيف وزنهم. وبمرور الوقت، أصبح…
-

فوائد وأساسيات اتباع حمية صحية لانقاص الوزن
•
فوائد وأساسيات اتباع حمية صحية لانقاص الوزن تعد الحمية الصحية لانقاص الوزن أمراً هاماً للكثير من الأشخاص الذين يسعون للحصول على وزن مثالي وجسم صحي. وتعتبر…
-

أفضل انظمة غذائية لزيادة الوزن بشكل صحي وآمن
•
انظمة غذائية لزيادة الوزن هي موضوع يشغل الكثير من الأشخاص الذين يعانون من نقص في الوزن. فالزيادة في الوزن بشكل صحي وآمن يتطلب اتباع نظام غذائي مناسب ومتواز…
-

أهمية تناول الوجبات الغذائية الصحية في حياة الإنسان
•
الوجبات الغذائية الصحية تلعب دوراً أساسياً في تحسين صحة الإنسان وضمان استمرارية عمل الجسم بكفاءة. إن تناول الوجبات الغذائية الصحية يسهم في توفير الطاقة الل…
-

نظام غذائي فعال لتخسيس الوزن بطريقة صحية
•
نظام غذائي فعال لتخسيس الوزن بطريقة صحية يعتبر النظام الغذائي من أهم العوامل التي تساعد على تحقيق الوزن المثالي والحفاظ على صحة الجسم. وبما أن التخسيس يعتب…
-

أهمية جمع وتحليل المعلومات الصحية لتحسين الخدمات الطبية
•
تعتبر معلومات صحية أساسية لتقديم خدمات طبية عالية الجودة وفعالة. فهي توفر نظرة شاملة عن الحالة الصحية للأفراد وتساعد في اتخاذ القرارات الطبية الصائبة. إذاً…
-
أفضل الطرق لعلاج تخسيس الوزن بشكل صحي
•
أفضل الطرق لعلاج تخسيس الوزن بشكل صحي تعتبر مشكلة الوزن الزائد والسمنة من أكثر المشاكل الصحية انتشاراً في العصر الحديث، وقد يكون لها تأثيرات سلبية على الصح…
-

أهمية الحصول على معلومات طبية دقيقة وموثوقة
•
أهمية الحصول على معلومات طبية دقيقة وموثوقة معلومة طبية قد تكون مفتاحاً في الحفاظ على صحة الإنسان وعلاج الأمراض، إذ تساعد على فهم حالة المريض وتحديد العلاج…
-

أهمية العناصر الغذائية الأساسية في الحفاظ على صحة الجسم
•
العناصر الغذائية الأساسية هي العناصر التي يحتاجها الجسم لضمان الحفاظ على صحته وسلامته. وتشمل هذه العناصر البروتين، الدهون، الكربوهيدرات، الفيتامينات، والمع…
-

تحسين الوزن من خلال النظام الغذائي: الخطوات الصحيحة
•
النظام الغذائي لزيادة الوزن هو موضوع يشغل الكثيرين في الوقت الحالي، حيث يعاني الكثيرون من مشكلة نقص الوزن وتحسين الوزن يمكن أن يكون تحدياً كبيراً. ومع ذلك،…
-

أهمية معلومات صحية غذائية لصحة الجسم والعقل
•
أهمية معلومات صحية غذائية لصحة الجسم والعقل المعلومات الصحية الغذائية تعد أساسية للحفاظ على صحة الجسم والعقل، حيث تلعب دوراً هاماً في توفير الغذاء الصحي ا…
-

أهمية اتباع نظام غذائي للتخسيس بشكل صحي
•
نظام غذائي للتخسيس يعتبر أحد الخطوات الأساسية التي يجب اتباعها لتحقيق الوزن المثالي والحفاظ على صحة الجسم. فالتخلص من الوزن الزائد بشكل صحيح ومستدام يتطلب…
-

فوائد الحمية الغذائية الصحية في تحسين الصحة واللياقة البدنية
•
الحمية الغذائية الصحية هي مفتاح لتحسين الصحة واللياقة البدنية. فهي تشكل أساساً أساسياً للحفاظ على جسم صحي ونشيط. وتتضمن الحمية الغذائية الصحية تناول مجموعة…
-

نظام صحي لانقاص الوزن: الطريقة الصحية لتحقيق الوزن المثالي
•
نظام صحي لانقاص الوزن: الطريقة الصحية لتحقيق الوزن المثالي تعتبر مشكلة الوزن الزائد والسمنة من أبرز المشاكل الصحية التي يواجهها الكثير من الأشخاص في الوقت…
-

نصائح صحية لتحسين جودة الحياة اليومية
•
نصائح صحية تعد من العوامل الأساسية التي تساهم في تحسين جودة الحياة اليومية، فالصحة هي أساس السعادة والراحة في الحياة. تعتبر النصائح الصحية أسلوب حياة يساعد…
-

استراتيجيات فعالة لزيادة الوزن بطرق صحية
•
تعتبر زيادة الوزن من الأمور التي تشغل بال الكثيرين في مجتمعنا، فقد تكون هذه المشكلة نتيجة لقلة الشهية أو العوامل الوراثية أو حتى نتيجة للتغذية الغير مناسبة…
-

كيفية تخسيس الوزن بطرق صحية وفعالة
•
طريقة تخسيس الوزن هي موضوع يشغل بال الكثير من الأشخاص في جميع أنحاء العالم، فالحفاظ على وزن صحي يعتبر أمراً مهماً للحفاظ على صحة الجسم والعقل. تعتمد طرق تخ…
-

أهمية الانظمه الغذائيه الصحية لصحة الجسم
•
تعتبر الانظمة الغذائية الصحية أساساً هاماً للحفاظ على صحة الجسم والحياة السليمة. فإن العناية بالتغذية السليمة تلعب دوراً فعالاً في الوقاية من الأمراض وتحقي…
-

نصائح طبية للحفاظ على صحة جيدة
•
نصائح طبية للحفاظ على صحة جيدة الصحة هي أهم ثروة يمتلكها الإنسان، ولذلك فإن الحفاظ عليها يتطلب الاهتمام بالعديد من الأمور اليومية. ومن أجل الحفاظ على صحة ج…
-

تعرف على أهمية الحياة الصحية وكيفية الحفاظ عليها
•
مقال عن الحياة الصحية تعتبر الحياة الصحية أمرًا أساسيًا للإنسان، حيث تؤثر بشكل كبير على جودة حياته وقدرته على الاستمتاع بكافة الأنشطة والتحديات التي تواجه…
-

فوائد اتباع نظام الغذائي الصحي لصحة الجسم
•
نظام الغذائي الصحي هو أساس الصحة الجيدة والحياة السليمة. فهو يلعب دوراً أساسياً في تحسين وصون صحة الجسم، وتقوية الجهاز المناعي، والوقاية من الأمراض المزمنة…
-

نظام غذائي فعال لفقدان الوزن بشكل صحي
•
نظام غذائي لفقدان الوزن هو موضوع يشغل الكثير من الأشخاص الذين يسعون للحصول على وزن صحي و جسم متناسق. يعتبر فقدان الوزن بشكل صحي و فعال أمرًا مهمًا للحفاظ ع…
-

أفضل نظام غذائي لانقاص الوزن بصحة وسرعة
•
نظام غذائي لانقاص الوزن هو أحد أهم العوامل التي يجب الانتباه إليها عند السعي نحو الوزن المثالي والحفاظ على صحة الجسم. وبما أن تخفيف الوزن يعتبر هدفا مهما ل…
-

فوائد وأهمية استخدام منتجات صحية لصحة الجسم
•
منتجات صحية هي عناصر أساسية للحفاظ على صحة الجسم والعقل. فهي توفر العناصر الغذائية الضرورية التي يحتاجها الجسم ليعمل بشكل صحيح وليحافظ على قوته ونشاطه. إن…
-

أهمية اتباع نظام غذائي صحي للحفاظ على الصحة
•
أهمية اتباع نظام غذائي صحي للحفاظ على الصحة تعدّ الغذاء الصحي والمتوازن أساساً أساسياً للصحة الجيدة. إنّ اتباع نظام غذائي صحي يلعب دوراً كبيراً في الوقاية…
-

فوائد وأسباب اتباع نظام غذائي صحي
•
فوائد وأسباب اتباع نظام غذائي صحي يعتبر اتباع نظام غذائي صحي أمراً بالغ الأهمية للحفاظ على صحة الجسم والعقل. فالتغذية السليمة تلعب دوراً كبيراً في تعزيز ا…
-

أهمية اتباع أنظمة غذائية متوازنة لصحة الجسم
•
انظمة غذائية متوازنة تلعب دوراً هاماً في الحفاظ على صحة الجسم وضمان استمرارية وظائفه بشكل صحيح. فهي توفر للجسم العناصر الغذائية الضرورية التي يحتاجها، مثل…
-

نظام غذائي فعال للتخلص من الوزن الزائد
•
نظام غذائي لأنقاص الوزن هو الخطوة الأولى للتخلص من الوزن الزائد وتحقيق الوزن المثالي بطريقة صحية وفعالة. يعتبر اتباع نظام غذائي متوازن ومناسب لاحتياجات الج…
-

أفضل نظام غذائي صحي لإنقاص الوزن بشكل سريع وآمن
•
نظام غذائي صحي لإنقاص الوزن هو أحد الوسائل الفعالة التي يمكن اللجوء إليها لتحقيق الوزن المثالي بشكل سريع وآمن. فإذا كنت تبحث عن الحل الأمثل للتخلص من الوزن…
-

نصائح فعالة لانقاص الوزن بطرق صحية
•
تطلق كلمة “لانقاص الوزن” العديد من الأفكار والتحديات التي يواجهها الكثيرون في محاولتهم للوصول إلى وزن مثالي وصحي. لكن الحقيقة أن هناك نصائح فعالة يمكن اتبا…
-

طرق فعالة لانقاص الوزن بطرق صحية وآمنة
•
طريقة انقاص الوزن هي إحدى الأمور المهمة التي يبحث عنها الكثيرون في سبيل تحسين صحتهم والحفاظ على قوامهم الجسدي. لقد أصبحت مشكلة زيادة الوزن والسمنة من أبرز…
-

نظام غذائي صحي لزيادة الوزن: دليلك الشامل
•
نظام غذائي صحي لزيادة الوزن هو موضوع له أهمية كبيرة في عصرنا الحالي، حيث يعاني الكثير من الأشخاص من نقص في الوزن وتحتاج إلى طرق صحية وآمنة لزيادة وزنهم. لذ…
-

أهمية الغذاء الصحي في حياة الإنسان وأثره على الصحة
•
إن الغذاء الصحي يعتبر أساساً أساسياً في حياة الإنسان، إذ يمثل الوقود الذي يحتاجه الجسم ليقوم بوظائفه بكفاءة وصحة جيدة. ورغم أن الغذاء يعتبر مجرد وجبات يتنا…
-

أفضل طريقة لانقاص الوزن بسرعة وبصحة
•
أسرع طريقة لانقاص الوزن إن فقدان الوزن بصحة وبسرعة يعتبر هدفاً مهماً للكثيرين، ولكن البحث عن الطريقة الأمثل والفعّالة قد يكون تحدياً. فالتخلص من الوزن الز…
-

نظام غذائي فعّال لنقصان الوزن بشكل صحي
•
نظام غذائي لنقصان الوزن هو أحد العوامل الرئيسية في تحقيق الوزن المثالي والصحة الجسدية الجيدة. يعتبر الاختيار الصحيح للأطعمة والتوازن الغذائي السليم جزءاً أ…
-

أهمية اتباع نظام غذائي صحي لصحة الجسم
•
أهمية اتباع نظام غذائي صحي لصحة الجسم نظام غذائي صحي يعتبر أساساً أساسياً للحفاظ على صحة الجسم والحفاظ على وظائفه بشكل جيد. فمن خلال تناول الأطعمة الصحية و…
-

تعرف على أنواع العسل المتوفرة وفوائدها المذهلة
•
انواع العسل المتوفرة وفوائدها المذهلة يُعتبر العسل من أهم المواد الطبيعية التي يمكن الحصول عليها، حيث يحتوي على العديد من العناصر الغذائية والمواد الفعالة…
-

أهمية الحصول على معلومات حول الصحة
•
معلومات عن الصحة تعتبر أمراً ضرورياً في حياة الإنسان، حيث تلعب دوراً هاماً في الحفاظ على صحته وسلامته. إن الحصول على معلومات دقيقة وموثوقة حول الصحة يساعد…
-

أهمية اتباع نظام غذائي صحي للحفاظ على الصحة
•
أتباع نظام غذائي صحي هو أمر أساسي للحفاظ على صحتنا وعافيتنا. فالغذاء الصحي يلعب دوراً كبيراً في تقوية جهاز المناعة، وتقليل خطر الإصابة بالأمراض المزمنة مثل…
-

أهمية استخدام موقع مقالات في تطوير المهارات البحثية والمعرفية
•
موقع مقالات يعتبر وسيلة مهمة في تطوير المهارات البحثية والمعرفية، حيث يوفر الموقع مجموعة كبيرة من المقالات والدراسات الأكاديمية التي تساعد الباحثين والدارس…
-

فوائد وأضرار حمية الكيتو: كل ما تحتاج إلى معرفته
•
حمية الكيتو: كل ما تحتاج إلى معرفته تعتبر حمية الكيتو واحدة من أحدث الاتجاهات في عالم الصحة والتغذية التي اكتسبت شهرة واسعة في الآونة الأخيرة. تقدم هذه الح…
-

فوائد وأنواع أنظمة غذائية صحية ومتوازنة
•
انظمة غذائية صحية ومتوازنة هي جزء أساسي من الحفاظ على صحة الجسم والعقل. تعد الفوائد الصحية لتناول وجبات غذائية متوازنة ومتنوعة لا تقدر بثمن، حيث إنها تساعد…
-

أفضل طرق لانقاص الوزن بشكل آمن وصحي
•
أفضل طريقة لانقاص الوزن إن فقدان الوزن والحفاظ على الوزن المثالي يعتبر هدفاً مهماً للكثير من الأشخاص في جميع أنحاء العالم، ولكن البحث عن أفضل طرق لانقاص ال…
-

فوائد نظام الكيتو للصحة والعافية
•
نظام الكيتو هو نظام غذائي يعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون الصحية والبروتينات. يعتبر نظام الكيتو من الأنظمة الغذائية الشهيرة التي تحظ…
-

أهمية اتباع نظام غذائي متوازن لصحة جيدة
•
نظام غذائي متوازن هو الأساس الأساسي للحفاظ على صحة جيدة والتمتع بحياة مستدامة. يلعب النظام الغذائي دوراً حاسماً في توفير العناصر الغذائية اللازمة للجسم وال…
-

أفضل نظام غذائي لفقدان الوزن بشكل صحي
•
أفضل نظام غذائي لانقاص الوزن يعتبر فقدان الوزن بشكل صحي وآمن أمرا مهما للعديد من الأشخاص الذين يعانون من زيادة الوزن. ولكن مع كثرة النظم الغذائية المتاحة،…
-

كيف تتجنب زيادة الوزن في فصل الشتاء؟
•
زيادة الوزن هي مشكلة تواجه الكثير منا خلال فصل الشتاء، حيث يميل الكثيرون إلى تناول الطعام الدسم والسكريات بكثرة مما يؤدي إلى زيادة الوزن. ولكن هناك بعض الط…
-

فوائد اتباع نظام غذائي صحي وتأثيره على الصحة
•
تعتبر النظام الغذائي الصحي أساساً أساسيا للحفاظ على صحة الإنسان والوقاية من الأمراض. فهو يلعب دوراً مهماً في تحسين وتعزيز الصحة العامة والشعور بالتنوير وال…
-

كيفية انقاص الوزن بشكل صحي وفعال: نصائح وأساليب
•
انقاص الوزن هو هدف يسعى اليه العديد من الأشخاص للحفاظ على صحة جيدة والحصول على جسم متناسق. ومع زيادة اهتمام الناس باللياقة البدنية والتغذية السليمة، أصبحت…
-

فوائد تخسيس الوزن وأساليب فعالة لتحقيقه
•
تخسيس الوزن هو هدف يسعى إليه الكثير من الأشخاص سواء لأسباب صحية أو جمالية. فإذا كنت تبحث عن فوائد تخسيس الوزن وأساليب فعالة لتحقيقه فأنت في المكان المناسب….
-

أفضل نظام غذائي صحي لانقاص الوزن بسرعة
•
يعتبر النظام الغذائي الصحي لانقاص الوزن من الأمور الأساسية التي يجب التركيز عليها للحفاظ على الصحة والوزن المثالي. فإذا كنت تبحث عن أفضل نظام غذائي صحي لان…
-

نظام غذائي متوازن لزيادة الوزن: كيفية زيادة الوزن بشكل صحي
•
نظام غذائي لزيادة الوزن يعتبر أمراً هاماً للأشخاص الذين يعانون من نقص في الوزن ويرغبون في زيادته بشكل صحي وآمن. فإذا كنت ترغب في زيادة وزنك بشكل صحي وتحسين…
-

فوائد وتحديات نظام غذائي لانقاص الوزن
•
نظام غذائي لانقاص الوزن هو مجموعة من الأطعمة والمشروبات التي تهدف إلى تقليل الوزن الزائد وتحسين الصحة العامة. يعتبر اتباع نظام غذائي صحي ومتوازن أمراً مهما…
-

كيفية تحقيق نظام غذائي صحي ومتوازن بشكل فعال
•
نظام غذائي صحي هو أساس الحياة الصحية والنشاط البدني، فإذا كنت تبحث عن كيفية تحقيق نظام غذائي صحي ومتوازن بشكل فعال، فأنت في المكان الصحيح. يعد النظام الغذا…
-

أفضل منتجات لزيادة الوزن وكيفية اختيارها بشكل صحي
•
منتجات لزيادة الوزن تعتبر من العناصر الهامة التي يبحث عنها الكثيرون في سبيل تحقيق هدفهم في زيادة وزنهم بشكل صحي وآمن. فعند اختيار أفضل منتجات لزيادة الوزن…
-

فوائد واستخدامات العسل الملكي الطبيعي: دليل شامل
•
فوائد واستخدامات العسل الملكي الطبيعي: دليل شامل يعتبر العسل الملكي الطبيعي من أهم المنتجات الطبيعية التي تحتوي على فوائد صحية عديدة. ويُعتبر الكلمة المفت…
-

أهمية اتباع نظام حياة صحية في تحسين الصحة والعافية
•
نظام حياة صحي يعتبر أساساً أساسياً لتحسين الصحة والعافية، ويشمل عدة عوامل مهمة مثل التغذية السليمة، وممارسة الرياضة بانتظام، والحفاظ على الوزن المثالي، وتج…
-

تأثير نظام الحياة الصحي على جودة الحياة
•
تأثير نظام الحياة الصحي على جودة الحياة يعتبر نظام الحياة الصحي من أهم العوامل التي تؤثر على جودة الحياة للأفراد. فالحفاظ على توازن وصحة الجسم يسهم في تحس…
-

المنتج الأمثل لفقدان الوزن بسرعة وفعالية
•
في بحث مستمر عن الحلول الفعالة لفقدان الوزن بشكل سريع وصحيح، يعتبر العثور على المنتج الأمثل لانقاص الوزن أمراً مهماً للكثير من الأشخاص. هناك العديد من المن…
-

أفضل أنواع العسل: اكتشف أنواع العسل الطبيعي وفوائدها المذهلة
•
أفضل أنواع العسل: اكتشف أنواع العسل الطبيعي وفوائدها المذهلة يعتبر العسل من أكثر المنتجات الطبيعية فائدة للإنسان، حيث يحتوي على العديد من المواد الغذائية…
-

فوائد وأنواع منتجات لانقاص الوزن: دليل شامل
•
منتجات لانقاص الوزن: دليل شامل تعتبر مشكلة الوزن الزائد من المشكلات الصحية التي تواجه الكثير من الأشخاص في العالم، ولذلك بات البحث عن منتجات لانقاص الوزن…
-

اختيار أفضل نوع عسل: دليلك للحصول على أفضل نوع من العسل
•
اختيار أفضل نوع عسل: دليلك للحصول على أفضل نوع من العسل إذا كنت تبحث عن أفضل نوع من العسل لتستخدمه في وصفاتك الطبخية أو للاستمتاع بفوائده الصحية، فقد وصلت…
-

اتباع نظام غذائي صحي لفقدان الوزن بطريقة فعالة
•
اتباع نظام غذائي صحي لانقاص الوزن هو أمر ضروري للحفاظ على صحة الجسم والوصول إلى الوزن المثالي. يعتمد فقدان الوزن الفعال على تناول الطعام الصحي والمتوازن، ب…
-

العسل: افضل الخيارات لتحسين صحتك وتعزيز جمالك
•
العسل: أفضل الخيارات لتحسين صحتك وتعزيز جمالك يعتبر العسل من أفضل المواد الطبيعية التي توفر العديد من الفوائد الصحية والجمالية. فهو ليس مجرد محلول للحلويات…
-

اكتشف أفضل أنواع العسل وفوائده المذهلة
•
أفضل أنواع العسل: اكتشف أفضل أنواع العسل وفوائده المذهلة يعتبر العسل من أكثر المواد الطبيعية فائدة للإنسان، حيث يحتوي على العديد من العناصر الغذائية والفو…
-

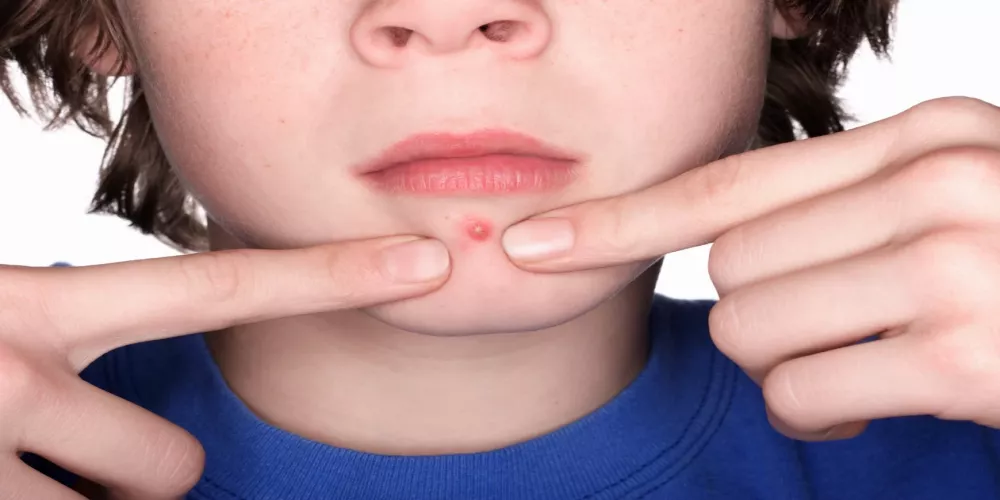
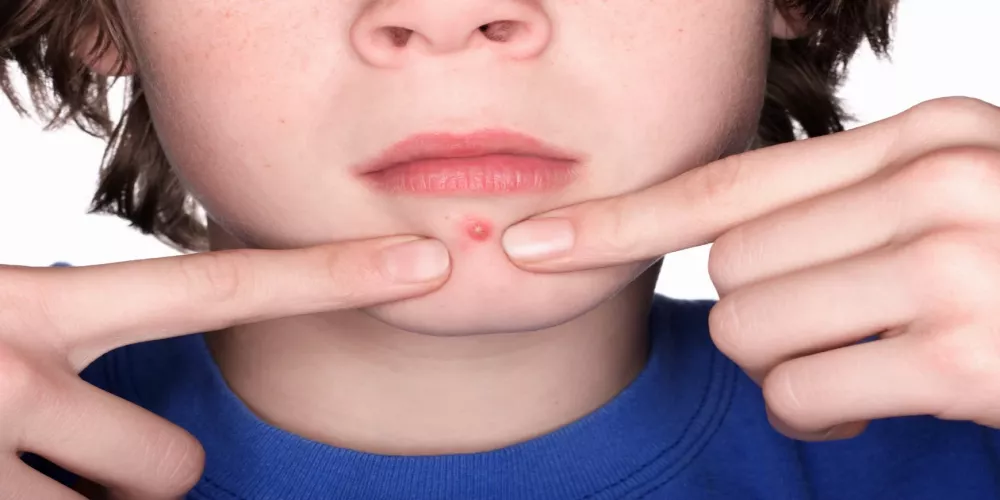
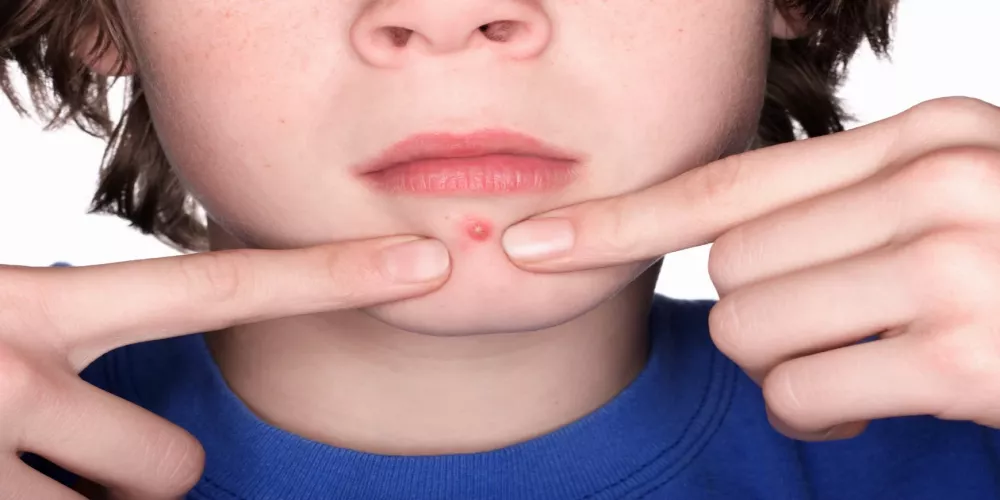
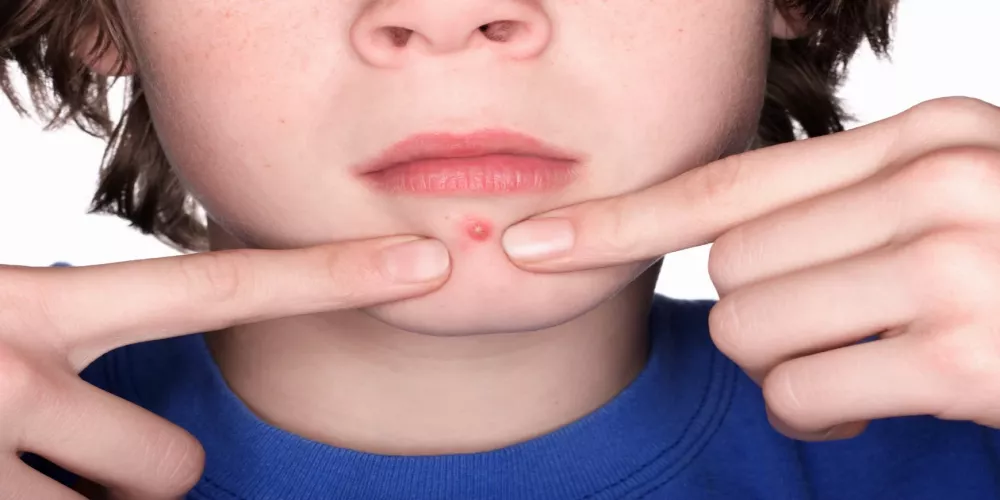
نظام غذائي فعال لعلاج حب الشباب
•
نظام غذائي لعلاج حب الشباب يُعتبر حب الشباب من أكثر المشاكل الجلدية شيوعًا بين الشباب والمراهقين، وقد يكون للتغيرات في نمط الحياة والنظام الغذائي دور كبير…
-

أفضل سيروم للبشرة الدهنية خفيفة ولا يسد المسام بأفضل سعر
•
البشرة الدهنية تعتبر تحديًا للكثيرين، حيث تتطلب عناية خاصة للحفاظ على نضارتها ومنع انسداد المسام. يعد اختيار السيروم المناسب خطوة أساسية في روتين العناية بالبشرة الدهنية، حيث يساعد في تحقيق التوازن المطلوب دون التسبب في انسداد المسام. في مقال اليوم نقدم لك أفضل أنواع السيروم المناسبة للبشرة الدهنية، ونقدم نصائح…
-

منتجات العناية بالبشرة أونلاين: أفضل الخيارات لبشرة صحية ومشرقة
•
العناية بالبشرة ليست مجرد رفاهية، بل هي خطوة أساسية للحفاظ على نضارة وصحة البشرة على المدى الطويل، و مع توفر العديد من المنتجات في الأسواق، قد يكون من الصعب اختيار الأفضل لنوع بشرتك واحتياجاتها و لحسن الحظ، أصبح بإمكانك شراء أفضل مستحضرات العناية بالبشرة أونلاين بسهولة عبر التطبيقات والمتاجر الإلكترونية،…
-

“فوائد الزيوت الطبيعية في العناية بالبشرة الدهنية”
•
الزيوت للبشرة الدهنية هي مكونات طبيعية تحتوي على خصائص مفيدة في العناية بالبشرة الدهنية. تُعتبر هذه الزيوت مصدرًا غنيًا بالعناصر الغذائية والفيتامينات الضر…
-

فوائد واستخدامات ماسكات طبيعية للبشرة والشعر
•
ماسكات طبيعية تعتبر ماسكات العناية بالبشرة والشعر من الوسائل الفعالة والطبيعية التي تعمل على تحسين وتجميل البشرة وتقوية الشعر. فهي تحتوي على مكونات طبيعية…
-

وصفة طبيعية لتنظيف البشرة من الحبوب
•
وصفة لتنظيف البشرة من الحبوب تعاني العديد من الأشخاص من مشكلة الحبوب التي تظهر على البشرة وتسبب لهم الكثير من الإزعاج والاحراج. ولكن بوجود الوصفات الطبيعي…
-
اكتشفي كيفية الحصول على منتجات لتنظيف البشرة التي تريدها
•
اكتشفي كيفية الحصول على منتجات لتنظيف البشرة التي تريدها واستخدم الكلمة المفتاحية التالية “عايزه حاجه لتنظيف البشره” في بداية المقدمة إذا كنتِ تبحثين عن م…
-

كيف تحصل على بشرة صافية باستخدام ماسك للوجه في البيت؟
•
ماسك للوجه في البيت هو واحد من أكثر الطرق شيوعاً للحصول على بشرة صافية ونضرة دون الحاجة للذهاب إلى صالون التجميل أو إنفاق مبالغ كبيرة على منتجات العناية با…
-

كيفية اختيار و استخدام ماسك ترطيب الوجه بطريقة صحيحة
•
ماسك ترطيب الوجه هو منتج جلدي مهم للحفاظ على صحة البشرة وترطيبها بشكل فعال. يعتبر اختيار واستخدام ماسك ترطيب الوجه بالطريقة الصحيحة أمرًا أساسيًا للحصول عل…
-

تنظيف البشرة قبل وبعد: الطريقة الأمثل للحصول على بشرة نقية ومشرقة
•
تنظيف البشرة قبل وبعد: الطريقة الأمثل للحصول على بشرة نقية ومشرقة تعتبر عملية تنظيف البشرة قبل وبعد من أهم الخطوات الواجب اتباعها للحفاظ على بشرة صحية وجم…
-

فوائد ماسكات الوجه: طريقة سهلة وفعالة لتحسين بشرتك
•
فوائد ماسكات الوجه: طريقة سهلة وفعالة لتحسين بشرتك تعتبر ماسكات الوجه أحد أهم العناصر في روتين العناية بالبشرة، حيث توفر مجموعة متنوعة من الفوائد التي تساع…
-
ماسكات للبشرة الطبيعية: الوصفات المثالية لبشرة صحية ومشرقة
•
ماسكات للبشرة الطبيعية: الوصفات المثالية لبشرة صحية ومشرقة تعتبر ماسكات البشرة الطبيعية واحدة من أهم وسائل العناية بالبشرة، حيث توفر لها العناية والتغذية…
-

فوائد واستخدامات ماسك لحبوب البشرة المختلطة
•
ماسك لحبوب البشرة المختلطة هو منتج تجميلي يعتمد على تركيبة طبيعية له العديد من الفوائد والاستخدامات الجمالية. يعتبر هذا المنتج خيارًا مثاليًا لمن يعانون من…
-
ماسكات فعالة للبشرة المختلطة للتخلص من الحبوب
•
ماسكات للبشرة المختلطة للحبوب تعتبر مشكلة البشرة المختلطة ووجود الحبوب من أكثر المشاكل الجلدية شيوعًا بين الناس، حيث تؤثر على مظهر البشرة وتسبب الإزعاج وا…
-
جمال الوجه الطبيعي بدون مكياج: أسرار الجمال الطبيعي
•
يعتبر الوجه الطبيعي بدون مكياج هدفًا مشتركًا بين الكثير من النساء حول العالم، حيث يسعى الكثيرون إلى تحقيق جمال طبيعي ينبعث من داخلهم دون الحاجة إلى استخدام…
-

وصفات تجميل الوجه في البيت: طرق طبيعية وفعالة لتحسين مظهر البشرة
•
تعتبر وصفات تجميل الوجه في البيت من الطرق الطبيعية والفعالة لتحسين مظهر البشرة، حيث تقدم هذه الطرق أفضل الحلول للعناية بالبشرة بمكونات طبيعية متوفرة في الم…
-

طرق فعالة لتنظيف البشرة بالطرق الطبيعية والفعالة
•
وصفات لتنظيف البشرة تعتبر البشرة من أهم العناصر التي تضيف جمالاً للشخص، ولذلك يجب الاهتمام بها بشكل جيد للحفاظ على نضارتها وصحتها. ومن أجل الحفاظ على البش…
-

أفضل كريمات للبشرة الدهنية الحساسة: حلول فعالة وآمنة
•
تعتبر مشكلة البشرة الدهنية الحساسة من المشاكل الشائعة التي تواجه الكثير من الأشخاص. ولذلك، فإن البحث عن أفضل كريمات للبشرة الدهنية الحساسة يعد أمراً مهماً…
-

فوائد استخدام مواد طبيعية لتنظيف البشرة وأهميتها
•
فوائد استخدام مواد طبيعية لتنظيف البشرة وأهميتها مواد طبيعية لتنظيف البشرة تعتبر من الخيارات المثالية للعناية بالبشرة، حيث توفر فوائد متعددة للجلد بدون تعر…
-

أفضل طرق تنظيف البشرة بالمنزل بطرق طبيعية وفعالة
•
أفضل طريقة لتنظيف البشرة بالمنزل تعد من الخطوات الأساسية للعناية بالبشرة، حيث تعمل على إزالة الشوائب والدهون الزائدة والخلايا الميتة والمكياج. وفي ظل الحيا…
-

تقنيات مذهلة لتنظيف البشرة في المنزل: الطرق الفعالة والمواد الطبيعية
•
تنظيف بشره في المنزل هو أمر مهم للحفاظ على صحة وجمال البشرة. ومع انتشار التقنيات المذهلة والمواد الطبيعية، أصبح بإمكاننا القيام بعناية فعالة للبشرة في راحة…
-

تقنيات ترطيب البشرة المختلطة: الحل الأمثل لبشرة متوسطة الدهون
•
تقنيات ترطيب البشرة المختلطة: الحل الأمثل لبشرة متوسطة الدهون تُعتبر تقنيات ترطيب البشرة المختلطة أمراً مهماً للحفاظ على صحة البشرة وتوازنها. فبشرة متوسطة…
-

جمال الطبيعة وروعة الألوان في فصل الربيع
•
تعتبر الطبيعة من أكثر الظواهر الطبيعية جمالاً وروعة في العالم، فهي تحمل في طياتها العديد من الصفات الطبيعية التي تجعلها محط أنظار الكثيرين. ومن بين فصول ال…
-

فوائد واستخدامات ماسك طبيعي للوجه: دليل شامل
•
ماسك طبيعي للوجه: دليل شامل يعتبر استخدام ماسك طبيعي للوجه أحد أسرار الجمال والعناية بالبشرة التي تستخدم منذ القدم. فهو يحتوي على مكونات طبيعية مفيدة للبشر…
-

طريقة تنظيف البشرة في المنزل بشكل طبيعي وفعال
•
طريقة عمل تنظيف للبشرة في المنزل تعتبر العناية بالبشرة أمراً هاماً للحفاظ على جمالها وصحتها، ويمكن تحقيق ذلك من خلال استخدام طرق طبيعية وفعالة لتنظيف البشر…
-
طرق تنظيف البشرة في المنزل بسهولة وفعالية
•
طريقه عمل تنظيف البشره في البيت تعتبر البشرة من أهم الأجزاء في جمال الإنسان، ولذلك يجب الاهتمام بها وتنظيفها بشكل منتظم. وفي ظل الحياة اليومية المزدحمة، ي…
-

أفضل ماسك لترطيب الوجه: دليل شامل لتحقيق بشرة ناعمة ومشرقة
•
ماسك لترطيب الوجه هو منتج أساسي في روتين العناية بالبشرة، فهو يساعد على إعادة ترطيب البشرة وتغذيتها بعمق، مما يجعلها ناعمة ومشرقة. ومن أجل تحقيق بشرة ناعمة…
-

أفضل الطرق لتنظيف البشرة بشكل فعال وصحي
•
معلومات عن تنظيف البشرة تعتبر العناية بالبشرة من العادات الصحية الضرورية للحفاظ على جمالها وصحتها. ومن أهم أساليب العناية بالبشرة هو تنظيفها بشكل فعال وصحي…
-

أفضل روتين لتفتيح البشرة: الخطوات والمنتجات المثالية
•
أفضل روتين لتفتيح البشرة: الخطوات والمنتجات المثالية تعتبر البشرة النضرة والمشرقة من أهم العوامل التي تساهم في إبراز جمال الوجه وثقة الشخص بنفسه. لذا، يبح…
-

طرق تنظيف البشرة الدهنية وعلاج الحبوب
•
تنظيف البشرة الدهنية من الحبوب يعتبر أمراً مهماً للحفاظ على صحة البشرة وجمالها. تعاني البشرة الدهنية من زيادة في إفراز الدهون الطبيعية مما يؤدي إلى ظهور ال…
-
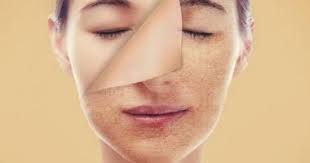
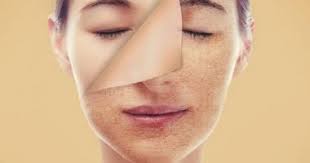
نصائح لتنظيف البشرة الجافة والحساسة في المنزل
•
تعتبر البشرة الجافة والحساسة من أكثر أنواع البشرة التي تحتاج إلى عناية واهتمام خاص، فهي تعاني من قشرة وجفاف شديدين قد يؤثران سلباً على مظهرها وصحتها. ولذلك…
-

طرق تنظيف البشرة للرجال بخطوات بسيطة وفعّالة
•
طريقة تنظيف البشرة للرجال تعتبر عملية تنظيف البشرة أمرًا أساسيًا للرجال للحفاظ على صحة ونضارة البشرة. فالعناية بالبشرة ليست مقتصرة على النساء فقط، بل تشمل…
-
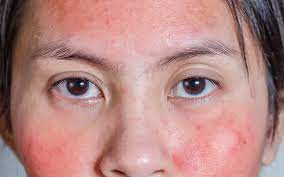
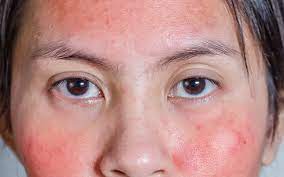
شكل البشرة الحساسة: أسبابها وطرق العناية بها
•
شكل البشرة الحساسة: أسبابها وطرق العناية بها تعتبر البشرة الحساسة من المشاكل الجلدية التي يعاني منها الكثيرون، وتتسبب في العديد من المشاكل والتهيجات الجلد…
-
نصائح لنضارة البشرة في يوم واحد
•
نضارة البشرة في يوم واحد: تعتبر البشرة من أهم العناصر التي تظهر جمال الشخص، ولذلك يسعى الكثيرون للحصول على بشرة نضرة وصحية. تعتمد نضارة البشرة على عدة عوام…
-

أفضل طرق ترطيب البشرة بشكل طبيعي وفعال
•
طريقة لترطيب البشرة تعتبر البشرة الجافة من المشاكل الشائعة التي يعاني منها الكثير من الأشخاص، وقد يكون اللجوء إلى المنتجات الكيميائية لترطيب البشرة هو الح…
-

فوائد وأضرار ماسكات لتهيج البشرة: كل ما تحتاج لمعرفته
•
فوائد وأضرار ماسكات لتهيج البشرة: كل ما تحتاج لمعرفته تعتبر ماسكات لتهيج البشرة أحد العلاجات الجمالية الشائعة التي يستخدمها الكثيرون لتحسين مظهر بشرتهم. ف…
-

أفضل مواقع العناية بالبشرة والشعر عبر الإنترنت
•
موقع للعناية بالبشرة والشعر تعتبر العناية بالبشرة والشعر من الأمور الأساسية التي يهتم بها الكثير من الناس، حيث تعتبر البشرة والشعر هما الجزء الأساسي من جم…
-

طرق تنظيف البشرة في المنزل للرجال
•
تنظيف البشرة في المنزل للرجال يعتبر أمراً مهماً للحفاظ على صحة البشرة وتجنب المشاكل الجلدية. فمع التلوث والاتساخات التي قد تتعرض لها البشرة يومياً، من الضر…
-

كيف تحافظ على بشرة مشرقة ونضرة طوال العام؟
•
البشرة مشرقة ونضرة هي أمنية كل امرأة، فهي تعكس الصحة والجمال الطبيعي للبشرة. في مواجهة التلوث والتقدم في العمر، يصبح الحفاظ على بشرة مشرقة ونضرة تحدياً كبي…
-

كيفية التعرف على البشرة الدهنية وأفضل العناية بها
•
معرفة البشرة الدهنية تعتبر البشرة الدهنية من الأنواع الشائعة للبشرة، وتتميز بإفراز الدهون بشكل زائد مما يؤدي إلى مظهر لامع ومسام متوسعة وظهور حب الشباب بش…
-

“تقنيات تنقية البشرة: الطرق الفعالة لتحسين جودة البشرة”
•
تنقية البشرة هي عملية أساسية للحفاظ على جودة وصحة البشرة. تعتبر تقنيات تنقية البشرة أحد الوسائل الفعالة لتحسين مظهرها وتخفيف مشاكلها. فالبشرة الجميلة والصح…
-

أهمية الاهتمام بالجسم وتأثيره على الصحة العامة
•
أهتمام بالجسم يعتبر الاهتمام بالجسم أمرًا ضروريًا للحفاظ على صحة جيدة ونمط حياة متوازن. فالجسم هو المعبد الذي يحتاج إلى العناية والاهتمام الدائم، وذلك لأن…
-

سكين كير للبشرة المختلطة: كيف تحافظين على بشرتك؟
•
سكين كير للبشرة المختلطة هي عناية خاصة بالبشرة التي تجمع بين الأماكن الدهنية والأماكن الجافة. تحافظ على توازن البشرة وتعالج المشاكل المتعلقة بها. إذا كنت ت…
-

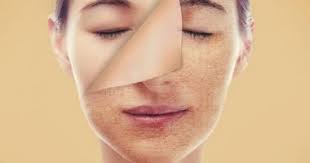
معلومات حول البشرة الدهنية: الأسباب والعناية الصحيحة
•
معلومات عن البشرة الدهنية: الأسباب والعناية الصحيحة تعتبر مشكلة البشرة الدهنية من المشاكل الشائعة التي تواجه الكثير من الأشخاص، وتعود أسبابها إلى عدة عوام…
-

مشاكل البشرة: الأسباب والعلاجات المناسبة لتحسين حالتها
•
مشاكل البشرة هي مشكلة شائعة تواجه الكثير من الأشخاص، حيث تتنوع هذه المشاكل بين حب الشباب والبقع الداكنة والجفاف والتجاعيد والحساسية. تعتبر هذه المشاكل مزعج…
-
كيفية العناية بالبشرة الدهنية بشكل فعال وسهل
•
تُعتبر البشرة الدهنية من أكثر أنواع البشرة انتشاراً بين الأشخاص، وهي تتطلب عناية خاصة ومنتجات مخصصة للعناية بها. يعاني الكثير من الأشخاص الذين يمتلكون بشرة…
-

مشاكل البشرة في فصل الصيف وكيفية التعامل معها
•
مشاكل البشرة في الصيف يعتبر فصل الصيف من أكثر الفصول التي تسبب مشاكل للبشرة، حيث تتعرض البشرة للعديد من التحديات الناتجة عن ارتفاع درجات الحرارة وتغيرات ا…
-

تقليل حاجز البشرة: كيف تحمي بشرتك من الضرر الخارجي
•
تقليل حاجز البشرة: كيف تحمي بشرتك من الضرر الخارجي تُعتبر البشرة الحاجز الطبيعي الذي يحمي جسم الإنسان من العوامل الخارجية المؤذية مثل الأشعة فوق البنفسجية…
-

وصفات طبيعية للعناية بالبشرة: أسرار الجمال الطبيعي
•
الجمال والعناية بالبشرة هما من أهم الأمور التي تهتم بها النساء في حياتهن اليومية. ومع التقدم في التكنولوجيا، أصبحت هناك الكثير من المنتجات الكيميائية التي…
-

أفضل 5 منتجات الوجه لتحسين مظهر بشرتك
•
منتجات الوجه هي مجموعة من المستحضرات التجميلية الرائعة التي تساعد في تحسين مظهر البشرة وتعزيز جمالها. تعتبر هذه المنتجات أساسية في روتين العناية بالبشرة، ح…
-
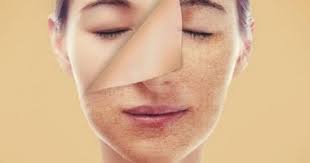
البشرة الحساسة الدهنية: كيف تعتني بها بشكل صحيح؟
•
البشرة الحساسة الدهنية: كيف تعتني بها بشكل صحيح؟ تعتبر البشرة الحساسة الدهنية من أكثر أنواع البشرة إصابة بالمشاكل والتحسس، وقد يكون العناية بها أمراً صعبا…
-

وصفات طبيعية للعناية بالبشرة: أسرار تجميلية فعالة
•
في عالمنا اليوم، يبحث الكثيرون عن الوصفات الطبيعية للعناية بالبشرة، حيث أصبحت العناية بالبشرة من أسرار التجميل الفعالة والمفضلة لدى الكثيرين. فعلى الرغم من…
-
فهم ماهي البشرة العادية و كيفية العناية بها
•
فهم ماهي البشرة العادية و كيفية العناية بها تُعتبر البشرة العادية من أكثر أنواع البشرة شيوعًا، حيث تتمتع بمزيج متوازن بين الزيوت والرطوبة، دون وجود أي مشاك…
-
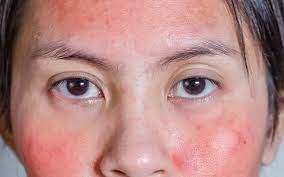
تحسين جودة العناية بالبشرة المختلطة: الأسرار لبشرة صحية ومتوازنة
•
بشرتي مختلطة، تلك المشكلة التي يواجهها الكثير من الأشخاص، فهي تتطلب رعاية خاصة للحفاظ على مظهرها الصحي والمتوازن. إن العناية بالبشرة المختلطة ليست أمرًا سه…
-

الخطوات الصحيحة للعناية بالبشرة: دليل شامل للعناية بالبشرة بشكل صحيح
•
الخطوات الصحيحة للعناية بالبشرة: دليل شامل للعناية بالبشرة بشكل صحيح إن العناية بالبشرة هي أمر مهم وضروري للحفاظ على جمالها وصحتها. فالبشرة هي العضو الأكب…
-

فوائد استخدام الصوره للبشره في العناية اليومية
•
مقدمة: تعتبر صوره للبشره من الخطوات الأساسية في روتين العناية اليومية بالبشرة. فهي تلعب دوراً هاماً في تنظيف البشرة وترطيبها، وكذلك في تغذيتها بالعناصر ال…
-

أهمية وفوائد روتين تنظيف البشرة اليومي
•
أهمية وفوائد روتين تنظيف البشرة اليومي يعتبر روتين تنظيف البشرة أمراً مهماً للحفاظ على صحة البشرة وجمالها، فالعناية اليومية بالبشرة تعتبر جزءاً أساسياً من…
-

روتين يومي للبشرة: العناية اليومية لبشرتك
•
روتين يومي للبشرة: العناية اليومية لبشرتك تعتبر العناية اليومية بالبشرة أمرًا أساسيًا للحفاظ على صحتها وجمالها. فالبشرة تحتاج إلى رعاية مستمرة واهتمام متج…
-

صور العناية بالبشرة: تعرف على أفضل الطرق للحفاظ على بشرتك
•
صور العناية بالبشرة: تعرف على أفضل الطرق للحفاظ على بشرتك تعتبر العناية بالبشرة من الأمور الهامة التي يجب أن يوليها الفرد اهتماماً كبيراً، فالبشرة هي الجز…
-

أهمية الاهتمام بالبشرة للرجال: دليل العناية الصحيحة
•
الاهتمام بالبشرة للرجال أصبح أمرًا مهمًا في عصرنا الحالي، حيث أن البشرة تعتبر بمثابة بطاقة الدعوة التي تعكس صحة الإنسان ونظافته. وبالرغم من أن العديد من ال…
-

كيفية الحفاظ على البشرة وتفتيحها بطرق طبيعية وفعالة
•
كيفية الحفاظ على البشرة وتفتيحها تعتبر البشرة من أهم الأعضاء في جسم الإنسان، حيث تحتاج إلى العناية والاهتمام المستمر للحفاظ على نضارتها وجمالها. ومن أجل ال…
-

روتين العناية بالبشرة المختلطة في الصيف: نصائح وخطوات فعّالة
•
يعتبر العناية بالبشرة في فصل الصيف أمرًا أساسيًا للحفاظ على مظهر صحي وجميل. ومن بين أنواع البشرة المختلطة التي تتطلب عناية خاصة خلال هذا الفصل هي البشرة ال…
-

العناية بالبشرة: روتين البشرة اليومي لبشرة صحية ومشرقة
•
روتين البشرة اليومي هو الخطوة الأساسية للحفاظ على بشرة صحية ومشرقة. فالعناية اليومية بالبشرة تعتبر من العوامل الأساسية للحفاظ على مظهرها الجميل وصحتها الجي…
-

العناية اليومية بالبشرة: أسرار ونصائح مصورة لبشرة صحية وجذابة
•
العناية اليومية بالبشرة بالصور تُعتبر البشرة من أهم العناصر التي تضفي جمالاً وصحة على الشكل العام للإنسان، ولذلك فإن الاهتمام بالعناية اليومية بالبشرة يعد…
-
روتين يومي للبشرة: العناية اليومية بالبشرة بخطوات بسيطة
•
روتين يومي للبشرة: العناية اليومية بالبشرة بخطوات بسيطة تعتبر العناية بالبشرة اليومية أمراً أساسياً للحفاظ على بشرة صحية ونضرة. فالعوامل الخارجية مثل الشم…
-

أهمية العناية بالبشرة: الطريقة الصحيحة للحفاظ على جمال وصحة البشرة
•
أهمية العناية بالبشرة: الطريقة الصحيحة للحفاظ على جمال وصحة البشرة تعد البشرة أحد أهم العناصر التي تعكس صحة وجمال الإنسان. فهي تعتبر الغلاف الخارجي الذي ي…
-

تسوق أفضل منتجات للجسم للعناية اليومية بجمالك
•
منتجات للجسم هي جزء أساسي من روتين العناية اليومية بالبشرة والجسم، فهي تساعد في الحفاظ على نضارة وجمال البشرة والحفاظ على صحة الجسم. تحتاجين إلى منتجات تلا…
-

أفضل كريمات تنظيف البشرة: اكتشفي منتجات العناية الفعالة لبشرة نقية وصحية
•
افضل كريمات تنظيف البشرة تعتبر البشرة من أهم الجوانب التي يجب على الإنسان الاعتناء بها، فهي المرآة التي تعكس صحة الإنسان وجماله. ومن أجل الحفاظ على بشرة ن…
-

فوائد البشرة الدهنية للرجال: كيف تستفيد منها في العناية بالبشرة
•
فوائد البشرة الدهنية للرجال: كيف تستفيد منها في العناية بالبشرة تعتبر البشرة الدهنية من الأنواع الشائعة لدى الرجال، وعلى الرغم من أنها قد تسبب بعض المشاكل…
-
ماسك الوجه لتنظيف البشرة الحساسة: الحل الفعال للعناية ببشرتك
•
ماسك لتنظيف البشرة الحساسة: الحل الفعال للعناية ببشرتك تعتبر البشرة الحساسة من أكثر أنواع البشرة التي تحتاج إلى عناية خاصة ومنتجات ملائمة لتنظيفها بلطف دو…
-

آثار وفوائد استخدام ماسك للبشرة الجافة
•
ماسك للبشرة الجافة هو منتج تجميلي يستخدم لترطيب وتنعيم البشرة التي تعاني من الجفاف. يعتبر استخدام ماسك للبشرة الجافة أمرًا مهمًا للحفاظ على صحة البشرة ومظه…
-
كيفية حل مشاكل البشرة الدهنية بطرق فعالة وطبيعية
•
مقالنا اليوم سيحدث عن كيفية حل مشاكل البشرة الدهنية بطرق فعالة وطبيعية. إن العديد من الأشخاص يعانون من مشاكل البشرة الدهنية التي تؤثر على مظهرهم وثقتهم بأن…
-
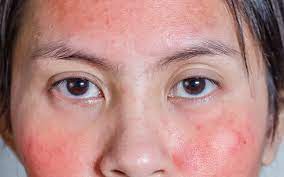
كيفية العناية بالبشرة للوجه الدهني
•
كيفية العناية بالبشرة للوجه الدهني يُعتبر الوجه الدهني من المشاكل الشائعة التي تواجه الكثير من الأشخاص، حيث يمكن أن يسبب الدهون الزائدة في البشرة الكثير من…
-

أفضل طرق علاج البشرة الجافة والحساسة بكل فعالية
•
يُعتبر علاج البشرة الجافة والحساسة من أهم الاهتمامات لدى الكثير من الأشخاص، حيث تعاني هذه البشرة من مشاكل مثل الجفاف والحكة والتهيج بسهولة. ولكن مع وجود ال…
-

كيفية علاج البشرة الدهنية بطرق طبيعية وفعالة
•
ماهو علاج البشره الدهنيه البشرة الدهنية هي مشكلة شائعة تواجه الكثير من الأشخاص وتتطلب عناية خاصة للحفاظ عليها بصحة جيدة. وقد يبحث الكثيرون عن طرق طبيعية وف…
-

تقنيات ترطيب البشرة الجافة والحساسة بفعالية
•
ترطيب البشرة الجافة والحساسة يعتبر أمراً هاماً للحفاظ على صحة البشرة وجمالها. تعتبر البشرة الجافة والحساسة من أكثر أنواع البشرة احتياجاً للعناية والترطيب ب…
-

طرق فعالة لعلاج البشرة التعبانة واستعادة نضارتها
•
يُعتبر علاج البشرة التعبانة أمرًا مهمًا للغاية للكثير من الأشخاص الذين يعانون من مشاكل في البشرة مثل الجفاف وفقدان النضارة. فمع تقدم التكنولوجيا وزيادة الو…
-

العناية بالبشرة الدهنية للرجال: نصائح ومنتجات مفضلة
•
العناية بالبشرة الدهنية للرجال: نصائح ومنتجات مفضلة تعتبر العناية بالبشرة الدهنية للرجال من الأمور المهمة التي يجب أخذها بعين الاعتبار، حيث تتطلب هذه البش…
-

أفضل منتجات العناية بالبشرة للحصول على بشرة صحية ومشرقة
•
إذا كنت تبحث عن الحصول على بشرة صحية ومشرقة، فإن الاهتمام بالعناية بالبشرة يعتبر أمراً أساسياً. تعتبر منتجات العناية بالبشرة من أهم العوامل في الحفاظ على ج…
-

سكين كير للبشرة الدهنية: طرق فعالة للعناية بالبشرة الدهنية
•
سكين كير للبشرة الدهنية هو موضوع يثير اهتمام الكثيرين، فالبشرة الدهنية تحتاج إلى عناية خاصة للحفاظ على نضارتها وصحتها. تعتبر البشرة الدهنية أكثر عرضة للحبو…
-

كيفية التخلص من روتين حب الشباب بطرق فعالة وآمنة
•
روتين حب الشباب هو مشكلة تواجه الكثير من الأشخاص، وقد يكون التعامل معها أمرًا صعبًا. إذا كنت تعاني من حب الشباب وتبحث عن طرق فعالة وآمنة للتخلص منه، فأنت ف…
-

أفضل منتجات العناية بالبشرة الجافة والحساسة لبشرة نضرة وصحية
•
منتجات العناية بالبشرة الجافة والحساسة هي جزء أساسي من روتين العناية بالبشرة، حيث تساعد على ترطيب البشرة وحمايتها من التهيج والجفاف. تعتبر البشرة الجافة وا…
-

أفضل الوصفات الطبيعية لعلاج البشرة
•
علاج البشرة هو موضوع مهم يهم الكثير من الناس، فالبشرة هي أكبر عضو في جسم الإنسان وتستحق العناية والاهتمام. تعاني الكثير من الأشخاص من مشاكل مختلفة في البشر…
-

أفضل منتجات العناية بالبشرة الجافة: اكتشفي العناية الفعالة والمنتجات المميزة
•
أفضل منتجات العناية بالبشرة الجافة: اكتشفي العناية الفعالة والمنتجات المميزة تعتبر البشرة الجافة من المشاكل الشائعة التي يعاني منها الكثير من الأشخاص، وتحت…
-
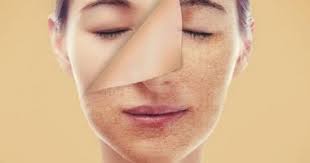
افضل ماسك للبشرة الدهنية: اكتشفي اسرار العناية الفعالة
•
افضل ماسك للبشرة الدهنية: اكتشفي اسرار العناية الفعالة تعتبر البشرة الدهنية من أكثر أنواع البشرة احتياجًا للعناية الفعالة والمنتجات المناسبة. ومن بين تلك…
-

فوائد واستخدامات كريمات ترطيب للبشرة الدهنية
•
في السنوات الأخيرة، أصبحت العناية بالبشرة من أهم العوامل التي توليها الكثير من الناس اهتمامًا كبيرًا، خاصةً عندما يتعلق الأمر بالبشرة الدهنية. إن البشرة ال…
-

أفضل منتجات سكين كير: تحقق البشرة النضرة والصحية
•
أفضل منتجات سكين كير: تحقق البشرة النضرة والصحية في عالم الجمال والعناية بالبشرة، تعتبر منتجات سكين كير من الأساسيات التي لا يمكن الاستغناء عنها. فهي تساع…
-

أفضل مجموعة منتجات للعناية بالبشرة الجافة: توصيات ونصائح
•
أفضل مجموعة للعناية بالبشرة الجافة: توصيات ونصائح تعتبر العناية بالبشرة الجافة أمرًا مهمًا للحفاظ على صحة وجمال البشرة. ومن أجل تحقيق ذلك، يُعتبر اختيار أ…
-

أفضل منتجات العناية بالبشرة الدهنية للرجال: اكتشف العناية المثالية
•
مع زيادة الاهتمام بالعناية الشخصية للرجال، أصبحت منتجات العناية بالبشرة الدهنية أكثر أهمية من أي وقت مضى. فالبشرة الدهنية تتطلب منتجات خاصة تساعدها على الت…
-
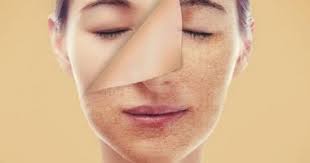
أهمية العناية بالجسم وتأثيرها على الصحة العامة
•
يعتبر “العناية بالجسم” مفتاحاً أساسياً للحفاظ على الصحة والعافية. فقد تأثرت عناصر العناية بالجسم بشكل كبير على الصحة العامة للإنسان. ومن المعروف أن الاهتما…
-

أهمية العناية بالجسم كله وأسرار الصحة والجمال
•
أهمية العناية بالجسم كله وأسرار الصحة والجمال تعتبر العناية بالجسم كله من الأمور الهامة التي يجب الانتباه إليها للحفاظ على الصحة والجمال. فالاهتمام بالبشر…
-
أفضل مجموعة للعناية بالبشرة الدهنية: الحل الأمثل لبشرة خالية من اللمعان
•
تعد مشكلة البشرة الدهنية من المشاكل الشائعة التي تواجه العديد من الأشخاص، حيث تتسبب في الإفراط في إفراز الزيوت الطبيعية وظهور اللمعان الغير مرغوب. ولحل هذه…
-

فوائد ونظام الكيتو دايت: دراسة جدول كيتو والتغذية الصحية
•
نظام الكيتو دايت أصبح من أبرز الاتجاهات الغذائية في الوقت الحالي، حيث يعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون والبروتينات. ويهدف هذا النظام…
-

تناول مأكولات لانقاص الوزن بطريقة صحية وفعالة
•
مأكولات لانقاص الوزن تعتبر الطرق الصحية والفعالة لفقدان الوزن من أبرز الأهداف التي يسعى إليها الكثيرون في مجتمعنا الحديث، فالحفاظ على وزن صحي يعتبر أمراً…
-

التحاليل المطلوبة قبل الدايت: دليلك لفهم الاحتياجات الصحية
•
التحاليل المطلوبة قبل الدايت: دليلك لفهم الاحتياجات الصحية تعد التحاليل الطبية اللازمة قبل البدء في أي نظام غذائي أمراً مهماً لضمان سلامة الفرد وتوافر احتي…
-

طرق فعالة لتخسيس الوزن بشكل صحي وسريع
•
طريقه لتخسيس الوزن هي هدف يسعى إليه الكثير من الأشخاص في مختلف أنحاء العالم. فالبحث عن طرق فعالة لتخسيس الوزن بشكل صحي وسريع يعتبر أمرا مهما للكثيرين، سواء…
-

جدول للتخسيس السريع: كيفية تحقيق أهدافك بفعالية
•
جدول للتخسيس السريع: كيفية تحقيق أهدافك بفعالية تعتبر عملية التخسيس من الأهداف الصعبة التي يسعى إليها الكثيرون، حيث يبحث الكثيرون عن وسائل وطرق فعالة لتحق…
-

أفضل طرق لتحقيق تخسيس بدون رياضة بنجاح
•
تخسيس بدون رياضة هو هدف يسعى اليه الكثير من الأشخاص الذين يرغبون في خسارة الوزن بشكل فعال وناجح. يعتبر البحث عن أفضل طرق لتحقيق تخسيس بدون رياضة تحدٍ كبير،…
-

برنامج تخسيس في أسبوع: خطوات ونصائح للحصول على الوزن المثالي
•
يعد برنامج تخسيس في أسبوع من البرامج الشهيرة التي يتجه إليها الكثيرون للحصول على الوزن المثالي والجسم المناسب. إن تخسيس الوزن في وقت قصير يحتاج إلى اتباع خ…
-

فوائد ومخاطر انظمة رجيم سريعة: الحقيقة والخيال
•
انظمة رجيم سريعة هي أحد الاتجاهات الغذائية التي تحظى بشعبية كبيرة في الوقت الحالي، حيث يسعى الكثيرون إلى فقدان الوزن بأسرع وقت ممكن. ومع زيادة انتشار هذه ا…
-

نصائح فعالة لنقص الوزن بشكل صحي
•
نصائح فعالة لنقص الوزن بشكل صحي تعتبر مشكلة زيادة الوزن والبحث عن طرق للتخلص منها من أكثر القضايا انتشاراً في العصر الحديث. ولكن من الضروري أن يكون هدف فقد…
-

فوائد الدايت: كيف يساعد التغذية السليمة في تحسين صحة الجسم؟
•
فوائد الدايت للجسم تُعتبر الدايت أحد العوامل الأساسية التي تسهم في تحسين صحة الجسم والحفاظ على لياقته. فالتغذية السليمة تلعب دوراً هاماً في تعزيز الصحة الع…
-

كيف تحقق تخسيس الوزن في شهر بطرق صحية وفعالة
•
تحقيق تخسيس الوزن في شهر يعتبر تحدًا كبيرًا للكثير من الأشخاص، ولكن من الممكن تحقيق ذلك بطرق صحية وفعالة. عندما يتعلق الأمر بفقدان الوزن في وقت قصير، يجب أ…
-

فوائد وأساليب تطبيق نظام رجيم صحي لحياة أفضل وأكثر صحة
•
يُعتبر النظام الغذائي الصحي أحد الأساليب الفعالة لتحسين جودة الحياة والحفاظ على الصحة العامة، ومن بين هذه الأنظمة الصحية المتبعة هو “نظام رجيم صحي”. فهو يع…
-

نظام رجيم في رمضان: كيف تحافظ على صحتك وتخسر الوزن؟
•
نظام رجيم في رمضان: كيف تحافظ على صحتك وتخسر الوزن؟ يعتبر شهر رمضان فرصة مهمة لكثير من الأشخاص لفقدان الوزن والحفاظ على صحتهم. فهو شهر يمتاز بالصيام النها…
-

فوائد الرجيم في رمضان: الطريقة الصحيحة للحفاظ على الصحة
•
فوائد الرجيم في رمضان: الطريقة الصحيحة للحفاظ على الصحة في شهر رمضان المبارك، يلتزم الكثيرون بالرجيم كوسيلة للحفاظ على الصحة واللياقة البدنية خلال الصيام….
-

وصفات جديدة لوجبات بدون كارب لتناول وجبة صحية
•
وجبة بدون كارب: وصفات جديدة لتناول وجبة صحية يعتبر تناول وجبات خالية من الكربوهيدرات أمراً مهماً للكثير من الأشخاص الذين يهتمون بصحتهم ويرغبون في تحسين نم…
-

فوائد رجيم بروتيني وكيفية اتباعه بشكل صحي
•
رجيم بروتيني هو نوع من الأنظمة الغذائية التي تركز على زيادة استهلاك البروتين وتقليل الكربوهيدرات والدهون. يُعتبر الرجيم البروتيني فعالاً في فقدان الوزن، زي…
-

فوائد وطريقة اتباع رجيم الماء للتخسيس الصحي
•
طريقة رجيم الماء يُعد رجيم الماء من الطرق الفعّالة التي تساهم في فقدان الوزن بشكل سريع وصحي. يقدم هذا النظام الغذائي العديد من الفوائد الصحية، إذ يعمل على…
-

كيف تتخسين في رمضان بفعالية وصحة؟
•
التخسيس في رمضان أمر يشغل بال الكثير من الناس، ففي هذا الشهر المبارك يكثر الانتباه للصحة واللياقة البدنية والروحية، ومن المعروف أن صيام رمضان قد يكون فرصة…
-

أفضل استراتيجيات الدايت في رمضان للحفاظ على الوزن
•
أثناء شهر رمضان، يصبح الصيام وتغيير نمط الحياة اليومية تحديًا كبيرًا للكثير من الناس الذين يسعون للحفاظ على وزنهم أو فقدان الوزن. ومن أجل تحقيق هذا الهدف،…
-

نظام رجيم أسبوعي: خطوات فعالة لتحقيق الوزن المثالي
•
نظام رجيم أسبوعي: خطوات فعالة لتحقيق الوزن المثالي يعد النظام الغذائي أحد العوامل الأساسية في تحقيق الوزن المثالي والحفاظ عليه. من أجل ذلك، يتبع الكثيرون…
-

نظام دايت صحي لتخسيس الوزن بشكل آمن وفعال
•
نظام دايت صحى للتخسيس تعتبر مشكلة الوزن الزائد من أكثر المشاكل الصحية شيوعاً في العصر الحديث، ويبحث الكثير من الأشخاص عن طرق آمنة وفعالة لفقدان الوزن بشكل…
-

فوائد وأضرار رجيم لتخسيس الوزن: دليل شامل
•
رجيم لتخسيس الوزن هو موضوع شائع ومثير للجدل في عالم الصحة والتغذية. حيث يسعى الكثيرون إلى اتباع نظام غذائي محدد لفقدان الوزن بسرعة، ولكن مع ذلك يثير هذا ال…
-

رجيم اسبوعي: كيف تتبع خطة تخفيف الوزن على مدار الأسبوع؟
•
رجيم اسبوعي هو أحد الأساليب الشائعة للحفاظ على الوزن وتخفيفه. يعتمد هذا النوع من الرجيم على تناول أطعمة معينة ومتابعة خطة غذائية محددة على مدار الأسبوع. فه…
-

أفضل 5 أكلات صحية لانقاص الوزن بشكل آمن وفعال
•
أكلات صحية لانقاص الوزن يعد الحفاظ على الوزن الصحي والمثالي من أهم الأولويات في حياة الإنسان، ولذلك يبحث الكثيرون عن الطرق الآمنة والفعالة لفقدان الوزن بش…
-

فوائد وأضرار رجيم الأربعة أيام: كل ما تحتاج معرفته
•
رجيم الأربعة أيام هو نوع من أنواع الرجيمات القصيرة المدة التي تستخدم لخسارة الوزن بسرعة. يهدف هذا النوع من الرجيمات إلى تقليل كمية السعرات الحرارية المتناو…
-

أفضل وجبات للتخسيس: اختيار الطعام الصحي لفقدان الوزن
•
أفضل وجبات للتخسيس: اختيار الطعام الصحي لفقدان الوزن تعتبر اختيار الوجبات الصحية من أهم العوامل التي تساهم في فقدان الوزن بشكل فعال وآمن. فالتغذية السليمة…
-

نظام “اكل التخسيس” الصحيح للحصول على الوزن المثالي
•
نظام “اكل التخسيس” الصحيح للحصول على الوزن المثالي يعتبر البحث عن الوزن المثالي وتحقيقه أمرًا مهمًا للكثير من الناس. ومن أجل الحصول على الوزن المثالي بشكل…
-

دايت الطوارئ: كيف تتجاوز أزمة الوزن الزائد بسرعة وسهولة
•
دايت الطوارئ: كيف تتجاوز أزمة الوزن الزائد بسرعة وسهولة تعتبر مشكلة الوزن الزائد أحد أكبر التحديات التي يواجهها الكثير من الأشخاص في مجتمعنا اليوم. فقد يك…
-

أفضل الحميات لفقدان الوزن بسرعة: نصائح وإرشادات
•
أفضل الحميات لفقدان الوزن بسرعة: نصائح وإرشادات إذا كنت تبحث عن طرق فعالة لانقاص الوزن بسرعة، فإن اختيار الحمية المناسبة يمكن أن يكون الخطوة الأولى نحو تح…
-

جدول رجيم الماء: دليلك لخسارة الوزن بشكل صحي وفعال
•
جدول رجيم الماء: دليلك لخسارة الوزن بشكل صحي وفعال إذا كنت تبحث عن طريقة فعالة وصحية لخسارة الوزن، فإن جدول رجيم الماء يمكن أن يكون الحل الأمثل لك. إن فقد…
-

فوائد وأضرار عمل الرجيم: دليل شامل
•
يعتبر عمل الرجيم من الأمور التي يلجأ إليها الكثيرون لتحسين وزنهم وتحسين صحتهم العامة. إلا أنه بالرغم من الفوائد التي يمكن أن يجنيها الفرد من عمل الرجيم، إل…
-
نظام صحي للتخسيس: طرق فعالة لخسارة الوزن بشكل صحي وآمن
•
نظام صحي للتخسيس: طرق فعالة لخسارة الوزن بشكل صحي إذا كنت تبحث عن طرق فعالة لفقدان الوزن بشكل صحي وآمن، فإن نظام صحي للتخسيس يمكن أن يكون الحل الأمثل لك….
-

نظام غذائي لانقاص الوزن مجاني: كيف تخسر الوزن بشكل صحي ومجاني
•
يُعتبر البحث عن نظام غذائي لفقدان الوزن مجانيًا أمرًا مهمًا للكثير من الأشخاص الذين يسعون لتحسين صحتهم والحفاظ على وزنهم بشكل صحي. فقدان الوزن بشكل صحي يتط…
-

أفضل انظمة غذائية للتخسيس في رمضان: كيف تحافظ على الوزن المثالي خلال الشهر الكريم
•
تعتبر شهر رمضان الكريم فرصة مثالية للعديد من الأشخاص لفقدان الوزن والحفاظ على الوزن المثالي. خلال هذا الشهر الفضيل، يمكن للأشخاص تطبيق أنظمة غذائية خاصة تس…
-

الوصفات الغذائية لانقاص الوزن: طرق صحية وفعالة لتحقيق الهدف
•
تعد الصحة واللياقة البدنية أموراً مهمة للكثيرين، ويبحث الكثيرون عن الوصفات الغذائية لانقاص الوزن التي تساهم في تحقيق أهدافهم بشكل صحي وفعال. فقد أصبحت وصفا…
-

جدول دايت رمضاني: كيف تحافظ على التغذية الصحية خلال الصيام
•
جدول دايت رمضاني: كيف تحافظ على التغذية الصحية خلال الصيام يعتبر شهر رمضان شهراً مباركاً ينتظره المسلمون بشوق ويحرصون على استغلاله للقرب من الله وتحقيق ال…
-

مواقع دايت: ماذا تقدم وكيف تستفيد منها؟
•
مواقع دايت تعتبر مصدراً هاماً للمعلومات والموارد التي تهدف إلى تحقيق الصحة واللياقة البدنية من خلال خطط غذائية وبرامج تمارين متنوعة. تقدم هذه المواقع مجموع…
-

نظام تخسيس في رمضان: كيف تحافظ على وزنك خلال الصيام؟
•
نظام تخسيس في رمضان: كيف تحافظ على وزنك خلال الصيام؟ تعتبر شهر رمضان المبارك فرصة رائعة للتخلص من الوزن الزائد والحفاظ على وزن مثالي، وذلك من خلال الالتزا…
-

خطة جدول دايت اسبوعي للتخلص من الوزن الزائد
•
جدول دايت أسبوعي هو أحد الأساليب الفعالة التي يمكن استخدامها للتخلص من الوزن الزائد. إذا كنت تبحث عن طريقة لتحسين نمط حياتك الغذائي والتخلص من السمنة، فإن…
-

فوائد وأنواع أطعمة انقاص الوزن الصحية
•
فوائد وأنواع أطعمة انقاص الوزن الصحية اطعمة انقاص الوزن هي الأطعمة التي تساعد في خسارة الوزن بشكل صحي وفعال. فقد يكون التخلص من الوزن الزائد أمراً صعباً ل…
-

كيفية تنفيذ رجيم صحي وفعال لفقدان الوزن بشكل آمن
•
كيفية عمل الرجيم الصحي يعتبر فقدان الوزن والحفاظ على وزن مثالي من أهم الأهداف التي يسعى إليها الكثيرون، إلا أن الطرق الصحية والفعالة لتحقيق ذلك قد تكون غام…
-

جدول رجيم اسبوعي لتحقيق الوزن المثالي واللياقة البدنية
•
جدول رجيم اسبوعي يُعتبر تحقيق الوزن المثالي واللياقة البدنية هدفًا مهمًا للكثير من الأشخاص، وتحقيق هذا الهدف يتطلب الالتزام بجدول رجيم اسبوعي محكم ومتوازن…
-

فوائد وأسرار رجيم الصحي للحصول على وزن مثالي
•
رجيم الصحي هو أسلوب حياة يساعد على تحقيق الوزن المثالي والحفاظ عليه بشكل دائم. يعتمد هذا النوع من الرجيم على تناول الطعام الصحي وممارسة الرياضة بانتظام. وم…
-

طرق فعالة للتخسيس في شهر رمضان
•
طريقة التخسيس في رمضان هي موضوع يثير اهتمام الكثير من الناس خلال هذا الشهر الكريم، حيث يبحث الكثيرون عن طرق فعالة لفقدان الوزن والحفاظ على الصحة واللياقة ا…
-

رجيم فعال للتخسيس في رمضان: الطريقة الصحيحة لفقدان الوزن
•
رجيم للتخسيس في رمضان هو موضوع شائع بين الكثير من الأشخاء الذين يسعون لخسارة الوزن وتحقيق اللياقة البدنية خلال شهر رمضان. يعتبر رمضان فرصة مثالية لتحقيق أه…
-

فوائد وأضرار رجيم يوم: كل ما تحتاج إلى معرفته
•
رجيم يوم هو نوع من أنواع الحمية الغذائية التي تهدف إلى خسارة الوزن في فترة زمنية قصيرة. يعتمد هذا النوع من الرجيم على تقليل كمية السعرات الحرارية المتناولة…
-

الرجيم السريع لفقدان الوزن: أسرار تخفيف الوزن بسرعة
•
الرجيم السريع لفقدان الوزن: أسرار تخفيف الوزن بسرعة البحث عن أساليب فعالة لفقدان الوزن أصبح أمرًا مهمًا للكثيرين في الوقت الحالي. يسعى الكثيرون إلى الحصول…
-

نظام رمضان: أفضل الطرق للحفاظ على صحتك خلال الصيام
•
نظام رمضان هو فترة مهمة في حياة المسلمين حول العالم، حيث يمارسون الصيام من الفجر حتى الغروب طوال شهر رمضان الكريم. وفي ظل هذه الفترة الخاصة، يحتاج الشخص إل…
-

“نظام سريع لانقاص الوزن: الحل الفعال لتحقيق الوزن المثالي”
•
نظام سريع لانقاص الوزن: الحل الفعال لتحقيق الوزن المثالي إذا كنت تبحث عن طريقة فعالة وسريعة لفقدان الوزن والوصول إلى الجسم المثالي الذي تحلم به، فإن نظام…
-

“رجيم للتخسيس في أسبوع: كيف تخسر الوزن بسرعة وبطريقة صحية؟”
•
رجيم للتخسيس في أسبوع هو موضوع يثير اهتمام الكثير من الأشخاص الذين يبحثون عن الطرق السريعة والصحية لفقدان الوزن. يعتبر فقدان الوزن في وقت قصير تحدٍ كبير لك…
-

فوائد وأسرار نظام دايت متوازن للحفاظ على الصحة
•
نظام دايت متوازن هو اساس العناية بالصحة والحفاظ عليها، فهو يعتبر الطريقة الأمثل لتحقيق الوزن المثالي وللعناية بالجسم والعقل. يتضمن النظام الغذائي المتوازن…
-

برنامج الرجيم الغذائي: كيفية الاستفادة من برنامج اكل للرجيم
•
برنامج اكل للرجيم هو أحد البرامج الغذائية التي تهدف إلى مساعدة الأشخاص في خسارة الوزن بطريقة صحية وفعالة. يعتمد هذا البرنامج على تنظيم نظام غذائي محدد ومتو…
-

أفضل أساليب الأكل الصحي للتخسيس بطريقة فعالة
•
الأكل الصحي للتخسيس هو موضوع يثير اهتمام الكثيرين في الوقت الحالي، حيث يسعى الكثيرون للحفاظ على وزنهم والتخلص من الوزن الزائد بطريقة صحية وفعالة. يعد اختيا…
-

جدول اكل للتخسيس: خطوات سهلة لتحقيق أهدافك الصحية
•
جدول اكل للتخسيس: خطوات سهلة لتحقيق أهدافك الصحية عند البحث عن طرق للتخسيس والحفاظ على الوزن المثالي، يعتبر جدول الطعام أحد الأدوات الأساسية التي تساعد في…
-

برنامج الدايت الصحي: خطوات بسيطة لتحقيق الوزن المثالي
•
برنامج الدايت الصحي: خطوات بسيطة لتحقيق الوزن المثالي يعاني الكثير من الأشخاص من مشكلة الوزن الزائد، ويبحثون بشكل دائم عن الحلول المناسبة للتخلص منها. ولذ…
-

طرق تناول الطعام المناسبة لفقدان الوزن
•
طرق تناول الطعام المناسبة لفقدان الوزن الاكل المناسب للتخسيس أصبحت مشكلة الوزن الزائد من أكثر المشاكل انتشاراً في المجتمعات الحديثة، ويعتبر فقدان الوزن أحد…
-

تجربة نظام للتخسيس في أسبوع: هل يعمل حقًا؟
•
تجربة نظام للتخسيس في أسبوع: هل يعمل حقًا؟ يعدّ “نظام للتخسيس في أسبوع” من البرامج الغذائية الشهيرة التي تهدف إلى تقليص الوزن بشكل سريع وفعال. يبحث الكثيرو…
-

طرق تناول الأكل الصحي للتخسيس بشكل فعال
•
اكل صحي للتخسيس تعتبر طرق تناول الأكل الصحي أساسية لتخسيس الوزن بشكل فعال وآمن، حيث تلعب العادات الغذائية السليمة دوراً كبيراً في تحقيق الهدف المنشود. فمن…
-

فوائد وأضرار الدايت الشهري لصحة الإنسان
•
الدايت الشهري هو أحد الأساليب الغذائية التي يلجأ إليها الكثيرون من أجل خسارة الوزن وتحسين الصحة العامة. يعتمد هذا النوع من الدايت على تناول كمية محددة من ا…
-

نظام غذائي متوازن للرجال: كيف تحافظ على صحتك ولياقتك؟
•
نظام غذائي للرجال يعتبر أحد العوامل المهمة في الحفاظ على صحة الجسم ولياقته. فالتغذية السليمة تلعب دوراً كبيراً في توفير العناصر الغذائية الضرورية للجسم وضم…
-

جدول لنقص الوزن في أسبوع: خطوات بسيطة لتحقيق الهدف
•
يعتبر جدول لنقص الوزن في أسبوع أمرًا مهمًا للكثير من الأشخاص الراغبين في تحسين صحتهم وتحقيق الوزن المثالي. ومن أجل تحقيق هذا الهدف، يمكن اتباع خطوات بسيطة…
-

وجبات صحية لتخفيف الوزن: اختيار الأطعمة الصحية للحفاظ على الوزن المثالي
•
وجبات صحية لتخفيف الوزن: اختيار الأطعمة الصحية للحفاظ على الوزن المثالي تعتبر الوجبات الصحية أحد العوامل الأساسية التي تساعد في خفض الوزن والحفاظ على الوز…
-

أسرار نجاح الريجيم الفعال: كيف تحقق نتائج مذهلة؟
•
ريجيم فعال، هذا ما يسعى اليه الكثيرون الذين يسعون إلى تحقيق نتائج مذهلة في خسارة الوزن والحفاظ على الصحة الجيدة. فالعديد منا يبحثون عن أسرار نجاح الريجيم ا…
-

تعلم طريقة لعمل رجيم صحي بسهولة
•
تعلم طريقة لعمل رجيم صحي بسهولة إذا كنت تبحث عن طريقة موثوقة وفعالة لتحقيق الوزن المثالي بطريقة صحية وآمنة، فإن تعلم طريقة لعمل رجيم صحي يعتبر خطوة مهمة في…
-

أهم 5 أنواع دايت لفقدان الوزن بشكل صحي
•
أنواع الدايت لخسارة الوزن تعتبر فقدان الوزن بشكل صحي أمرًا مهمًا للكثير من الأشخاص الراغبين في الحفاظ على صحتهم وشكلهم الجسدي. ولهذا الغرض، تتوفر العديد م…
-

رجيم حرق الدهون: طرق فعالة لتحقيق النتائج المرجوة
•
رجيم حرق الدهون: طرق فعالة لتحقيق النتائج المرجوة تعتبر مشكلة السمنة وزيادة الوزن من أبرز القضايا الصحية التي تواجه الكثير من الأشخاص في العصر الحالي، وبال…
-

طريقة عمل دايت فعالة للتخسيس والحفاظ على الوزن
•
طريقة عمل دايت للتخسيس تعتبر عملية التخسيس والحفاظ على الوزن المثالي من أهم الأهداف التي يسعى الكثيرون لتحقيقها. ولذلك، يبحث الكثير من الأشخاص عن طرق فعالة…
-

فوائد وأضرار رجيم بعد رمضان وكيفية تجنبها
•
رجيم بعد رمضان هو موضوع يثير اهتمام الكثيرين بعد انتهاء شهر الصيام والتقدير. يحمل هذا الفترة الكثير من الفوائد والأضرار على الصحة، فبينما يمكن للرجيم أن يس…
-

رياضة ورجيم: الطريقة الصحية لخسارة الوزن خلال شهر
•
يعتبر فقدان الوزن والحفاظ على الوزن المثالي من أهم الأهداف التي يسعى إليها العديد من الأشخاص. ومن أجل تحقيق ذلك، يعتبر الرياضة والرجيم الصحي والمتوازن أهم…
-

أفضل نظام غذائي لتخسيس الوزن بشكل صحي وفعال
•
أفضل نظام غذائي لتخسيس الوزن بشكل صحي يعد من الأمور الهامة التي يبحث عنها الكثيرون في مسعى لتحسين صحتهم والحصول على جسم متناسق. يعتبر اتباع نظام غذائي مناس…
-

النصائح لاتباع عمل دايت لتخفيف الوزن بشكل صحي
•
العمل دايت لتخفيف الوزن هو موضوع يشغل بال الكثيرين في وقتنا الحالي، حيث يسعى الكثيرون للحصول على وزن صحي ومتوازن. ولكن من الضروري أن يكون العمل دايت هذا بش…
-

أفضل دايت للتخسيس: الوصفات الصحية والنصائح الفعالة
•
أفضل دايت للتخسيس: الوصفات الصحية والنصائح الفعالة تعد الحمية الغذائية من أهم العوامل التي تساهم في فقدان الوزن بشكل صحي وآمن. ومن أجل تحقيق أفضل النتائج،…
-
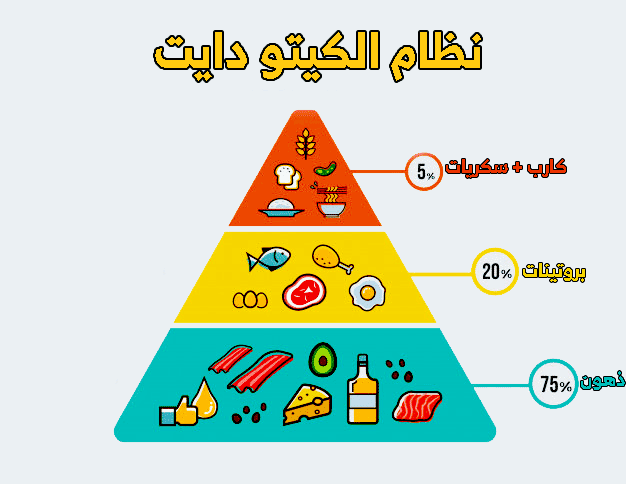
تحدي الـ ٣٠ يوم: كيف تحقق أهدافك من خلال الـ دايت ٣٠ يوم؟
•
تحدي الـ ٣٠ يوم: كيف تحقق أهدافك من خلال الـ دايت ٣٠ يوم؟ يعتبر الـ دايت ٣٠ يوم تحدياً شهيراً للعديد من الأشخاص الذين يسعون لتحقيق أهدافهم الصحية والرياضي…
-

أفضل نظام غذائي لفقدان الوزن بسرعة وبصورة صحية
•
أحلى نظام غذائي للتخسيس يعد فقدان الوزن بصورة صحية وسريعة من أهم الأهداف التي يسعى إليها الكثيرون للحفاظ على صحتهم وشكلهم الجسدي. ومن أجل تحقيق هذا الهدف،…
-

جدول الرجيم الصحي: كيفية تنظيم نظام غذائي متوازن وصحي
•
جدول الرجيم الصحي: كيفية تنظيم نظام غذائي متوازن وصحي إذا كنت تبحث عن طريقة فعالة لتنظيم نظام غذائي صحي ومتوازن، فإن جدول الرجيم الصحي يمكن أن يكون الحل ا…
-

نظام غذائي للتخسيس في رمضان: كيف تحافظ على وزنك خلال الشهر الفضيل
•
نظام غذائي للتخسيس في رمضان تعد شهر رمضان شهرًا مباركًا يأتي فيه المسلمون للصيام والتقرب إلى الله. ومع ذلك، قد يواجه البعض تحديات في الحفاظ على وزنهم أثناء…
-

أفضل نظام غذائي للتخسيس: كيف تخسر الوزن بشكل صحيح؟
•
أفضل نظام غذائي للتخسيس هو موضوع يشغل الكثير من الناس الذين يبحثون عن طرق صحية لفقدان الوزن بشكل فعال. يعاني الكثيرون من مشاكل البدانة وزيادة الوزن، ولذلك…
-

“أحدث أنظمة الدايت: تحقيق النتائج المذهلة بسهولة”
•
أحدث أنظمة الدايت: تحقيق النتائج المذهلة بسهولة تعاني الكثير من الأشخاص من مشكلة الوزن الزائد والدهون الزائدة في الجسم، ولذلك يبحثون دائما عن أحدث أنظمة ا…
-

أفضل نظام للتخسيس: كيف تخسر الوزن بطريقة صحية وفعالة
•
أفضل نظام للتخسيس: كيف تخسر الوزن بطريقة صحية وفعالة إن فقدان الوزن بطريقة صحية وفعالة يعتبر تحديًا كبيرًا للكثير من الأشخاص، حيث تتنوع النصائح والحلول ال…
-

فوائد نظام رجيم صحي لتحسين الصحة والعافية
•
فوائد نظام رجيم صحي لتحسين الصحة والعافية نظام رجيم صحي يعتبر أحد الوسائل الفعالة للحفاظ على الصحة والعافية. فهو يساعد على تحقيق الوزن المثالي وتقليل مخاط…
-
أفضل أنظمة الدايت لتحقيق الوزن المثالي والصحة الجيدة
•
أفضل أنظمة الدايت لتحقيق الوزن المثالي والصحة الجيدة إن الحفاظ على وزن صحي ومثالي يعتبر أمراً مهماً للكثير من الأشخاص، حيث يساهم في الحفاظ على الصحة الجيدة…
-

نظام رجيم فعال للتخسيس بسرعة وبطريقة صحية
•
نظام رجيم للتخسيس هو موضوع يشغل الكثير من الأشخاص الذين يبحثون عن الوصول إلى وزن مثالي وصحي. يعتبر البحث عن نظام رجيم فعال للتخسيس بسرعة وبطريقة صحية أمراً…
-

أنواع الأنظمة الغذائية: الخيار المناسب لصحتك
•
أنواع الأنظمة الغذائية: الخيار المناسب لصحتك تعتبر الأنظمة الغذائية أساساً مهماً في الحفاظ على الصحة واللياقة البدنية للإنسان. فهي تلعب دوراً حاسماً في تو…
-

جدول الاكل للتخسيس: كيفية تصميم خطة غذائية فعالة ومتوازنة؟
•
جدول الاكل للتخسيس: كيفية تصميم خطة غذائية فعالة ومتوازنة؟ إذا كنت تبحث عن طريقة فعالة ومتوازنة لخسارة الوزن، فإن تصميم جدول الأكل الخاص بك يمكن أن يكون ا…
-

أفضل أنظمة للتخسيس: الطرق الفعالة لفقدان الوزن
•
أفضل أنظمة للتخسيس: الطرق الفعالة لفقدان الوزن إذا كنت تبحث عن أفضل الأنظمة للتخسيس والطرق الفعالة لفقدان الوزن، فأنت في المكان الصحيح. يعتبر فقدان الوزن و…
-

جدول لعمل الرجيم: كيفية تنظيم نظام غذائي فعّال
•
جدول لعمل الرجيم: كيفية تنظيم نظام غذائي فعّال يعتبر تنظيم نظام غذائي من أهم الخطوات التي يجب اتباعها لتحقيق الوزن المثالي والحفاظ على الصحة. ولذلك، يأتي…
-

أهمية اتباع دايت صحي للتخسيس بشكل فعال وآمن
•
أن تتبع دايت صحي للتخسيس بشكل فعال وآمن هو خطوة مهمة للحفاظ على الصحة والوزن المثالي. فالدايت الصحي يساعد على تقليل الدهون في الجسم وزيادة الطاقة واللياقة…
-

أنظمة دايت مختلفة: اختيار النظام الغذائي المناسب لك
•
انظمة دايت مختلفة يواجه الكثير منا تحدي اختيار النظام الغذائي المناسب الذي يساعده على تحقيق الوزن المثالي والحفاظ عليه. فهناك العديد من الأنظمة الغذائية ا…
-

برامج غذائية للتخسيس بطرق صحية وفعّالة
•
برامج غذائية لانقاص الوزن تعتبر أحد أهم الخطوات في سبيل الحصول على وزن صحي وجسم متناسق. فقد يكون التخلص من الوزن الزائد أمرًا صعبًا ومرهقًا ولذلك يأتي دور…
-

طريقة عمل نظام غذائي صحي لفقدان الوزن
•
تعتبر طريقة عمل نظام غذائي صحي لفقدان الوزن أمرًا مهمًا للكثير من الأشخاص الذين يسعون لتحسين صحتهم والحصول على وزن مثالي. يعتمد نجاح هذه العملية على تحديد…
-

جدول تخسيس الوزن: خطوات فعّالة لفقدان الوزن بشكل صحي وآمن
•
جدول تخسيس الوزن: خطوات فعّالة لفقدان الوزن بشكل صحي وآمن يعتبر فقدان الوزن والحفاظ على وزن صحي ومتوازن أمراً مهماً للكثيرين في مجتمعنا اليوم. فالوزن الزا…
-

كيف يمكنك الاستفادة من نظام تخسيس غذائي؟
•
نظام تخسيس غذائي هو أحد الوسائل الفعالة التي يمكن للأشخاص اللجوء إليها لفقدان الوزن بطريقة صحية وآمنة. فإذا كنت تبحث عن طريقة لفقدان الوزن والحفاظ على وزنك…
-

أهمية النظام الغذائي الصحي لفقدان الوزن بشكل آمن وفعال
•
النظام الغذائي الصحي للتخسيس يعد أمراً بغاية الأهمية لمن يرغب في فقدان الوزن بشكل آمن وفعال، حيث يلعب الغذاء دوراً حاسماً في عملية التخسيس. فهو ليس مجرد وس…
-

نظام حمية غذائي لتحقيق إنقاص الوزن بصحة
•
نظام حمية غذائي لإنقاص الوزن إذا كنت تبحث عن طريقة صحية وفعالة لتحقيق إنقاص الوزن، فإن الحمية الغذائية تعتبر خياراً رائعاً لتحقيق ذلك. إن الحمية الغذائية ا…
-

فوائد وأهمية البروتين في الدايت للحفاظ على الصحة
•
دايت البروتين هو نوع من الحمية الغذائية الذي يولي اهتماما كبيرا بتناول البروتين كمكون أساسي في الوجبات اليومية. يعتبر البروتين أحد أهم المغذيات التي يحتاجه…
-

كيف تختار افضل رجيم في رمضان؟
•
افضل رجيم في رمضان رمضان شهر مبارك يأتي معه فرصة لتحسين العادات الغذائية والحصول على نتائج جيدة في فقدان الوزن. ولكن كيف يمكن اختيار أفضل رجيم في رمضان؟ ي…
-

طريقة رجيم صحي لتخفيف الوزن بشكل مستدام
•
طريقة رجيم صحي لتخفيف الوزن بشكل مستدام إذا كنت تبحث عن طريقة فعالة لتخفيف وزنك بشكل صحي ومستدام، فإن طريقة رجيم الصحي تعتبر الخيار الأمثل. فالرجيم الصحي…
-

أفضل نظام غذائي صحي لفقدان الوزن بشكل آمن
•
ايجاد أفضل نظام غذائي صحي لانقاص الوزن قد يكون تحديًا كبيرًا للكثير من الأشخاص الذين يسعون لتحسين صحتهم ومظهرهم. تختلف الحاجات الغذائية من شخص لآخر، ولا يو…
-

جدول خسارة الوزن: كيفية تحقيق النتائج المرغوبة بفعالية
•
جدول خسارة الوزن: كيفية تحقيق النتائج المرغوبة بفعالية يعتبر الحفاظ على وزن صحي ومتوازن أمرًا مهمًا للكثير من الناس، ولذلك فإن جدول خسارة الوزن يعتبر أداة…
-

فوائد وأنواع الانظمة الغذائية للتخسيس
•
الانظمة الغذائية للتخسيس هي الموضوع الذي يشغل بال العديد من الأشخاص الراغبين في فقدان الوزن والحفاظ على صحتهم. فقدان الوزن يعتمد بشكل كبير على النظام الغذا…
-

نظام غذائي فعال للتخسيس والحفاظ على الوزن
•
أريد نظام غذائي للتخسيس يعد البحث عن طرق فعالة لفقدان الوزن والحفاظ عليه من أهم الأهداف التي يسعى إليها الكثيرون. فقد يكون من الصعب العثور على نظام غذائي ي…
-

أفضل برنامج لخسارة الوزن: تحقق من النتائج المدهشة الآن
•
يعتبر البحث عن برنامج فعال لفقدان الوزن أمرًا مهمًا للكثير من الأشخاص الذين يبحثون عن تحسين صحتهم وشكلهم البدني. من خلال استخدام الكلمة المفتاحية “أفضل برن…
-

جدول نظام غذائي لانقاص الوزن: تخطيط غذائي فعال لتحقيق الهدف المثالي
•
جدول نظام غذائي لانقاص الوزن تعتبر عملية فقدان الوزن والحفاظ عليه من التحديات الصعبة التي يواجهها الكثيرون في حياتهم اليومية. ولذلك، يعتبر تخطيط غذائي فعال…
-

فوائد رجيم قليل الكربوهيدرات وغني البروتين للصحة واللياقة البدنية
•
يُعد رجيم قليل الكربوهيدرات وغني البروتين من الأنظمة الغذائية التي تحظى بشعبية كبيرة في عالم الصحة واللياقة البدنية. يُعتبر هذا النوع من الرجيم مفيدًا للكث…
-

نظام غذائي صحي لتخفيف الوزن: 10 خطوات لنجاح الرégime الصحي
•
نظام غذائي صحي لفقدان الوزن تعتبر مشكلة زيادة الوزن والسمنة من أبرز المشاكل التي تواجه الكثير من الأشخاص في العصر الحديث نتيجة لنمط الحياة الغير صحي وتناول…
-

فوائد وأساليب استخدام جدول نظام دايت لتحقيق أهداف اللياقة والصحة
•
جدول نظام دايت هو أداة مهمة وفعالة يمكن استخدامها لتحقيق الأهداف الصحية واللياقة. فهو يساعد في تنظيم وتنظيم النظام الغذائي بشكل فعال، مما يجعله أداة حيوية…
-

نظام غذائي صحي لانقاص الوزن خلال شهر واحد: دليل وخطوات فعّالة
•
نظام غذائي صحي لانقاص الوزن لمدة شهر يعتبر الحفاظ على وزن صحي ومتوازن من أهم الأهداف التي يسعى الكثيرون لتحقيقها، وخاصة عندما يتعلق الأمر بفقدان الوزن الز…
-

نظام غذائي فعال لتخسيس الوزن بصحة واستمرارية
•
نظام غذائي للتخسيس هو خطوة أساسية في رحلة فقدان الوزن بصحة واستمرارية. فإذا كنت تبحث عن طريقة فعالة لتحقيق ذلك، فإن اتباع نظام غذائي متوازن وملائم يمكن أن…
-

نظام غذائي فعّال لخسارة الوزن في شهر واحد
•
تعتبر فقدان الوزن في وقت قصير تحدياً كبيراً للكثير من الناس، لكن باستخدام نظام غذائي فعّال ومتوازن يمكن تحقيق هذا الهدف بنجاح. إذا كنت تبحث عن نظام غذائي ل…
-

جدول نقص الوزن: دليلك الشامل لفقدان الوزن بطرق آمنة وفعّالة
•
جدول نقص الوزن: دليلك الشامل لفقدان الوزن بطرق آمنة وفعّالة تعتبر مشكلة زيادة الوزن والبحث عن طرق فعّالة للتخلص من الوزن الزائد من أكثر القضايا الصحية شيو…
-

ما هو دايت قليل الكارب وكيف يمكن أن يساعدك في خسارة الوزن؟
•
تعتبر الدايت قليل الكارب واحدة من أنواع الحميات الغذائية التي تهدف إلى تقليل استهلاك الكربوهيدرات وزيادة استهلاك البروتينات والدهون. يهدف هذا النوع من الحم…
-

برنامج رائع لتخفيف الوزن وتحقيق الرشاقة
•
برنامج للرجيم وتخفيف الوزن هو الحل الأمثل للأشخاص الذين يعانون من مشاكل الوزن الزائد ويرغبون في تحقيق الرشاقة واللياقة البدنية. إن الحفاظ على وزن صحي ومتوا…
-

رجيم فعال لإنقاص الوزن في شهر: كيفية تحقيق الهدف بنجاح
•
رجيم فعال لإنقاص الوزن في شهر: كيفية تحقيق الهدف بنجاح إذا كنت تبحث عن طريقة فعالة لخسارة الوزن في وقت قصير، فإنّ رجيم لإنقاص الوزن في شهر قد يكون الحل الأ…
-

أهمية الجدول الغذائي قليل الكربوهيدرات في الحفاظ على صحتك
•
يعتبر جدول نظام غذائي قليل الكربوهيدرات أحد العوامل الهامة في الحفاظ على صحتنا والوقاية من العديد من الأمراض. فالكربوهيدرات تلعب دوراً أساسياً في تحديد مست…
-

نظام غذائي فعال لتخفيف الوزن بشكل صحي
•
نظام غذائي لفقدان الوزن يعتبر تخفيف الوزن والحفاظ على وزن صحي أمرًا مهمًا للكثير من الأشخاص، ولذلك فإن البحث عن نظام غذائي فعال لتحقيق ذلك يعتبر من الأمور…
-

جدول الوجبات الصحية لشهر كامل: تنظيم غذائي متوازن للحفاظ على الصحة
•
جدول الوجبات الصحية لشهر كامل: تنظيم غذائي متوازن للحفاظ على الصحة يعتبر تنظيم الطعام واختيار الوجبات الصحية أمرًا مهمًا للحفاظ على صحة الجسم والوقاية من ا…
-

نظام اكل للتخسيس: كيفية تحقيق النتائج المرجوة بطريقة صحية
•
نظام اكل للتخسيس: كيفية تحقيق النتائج المرجوة بطريقة صحية إذا كنت تبحث عن طريقة للتخلص من الوزن الزائد بطريقة صحية وفعالة، فإن النظام الغذائي يعتبر أساسيا…
-

كيفية إنشاء جدول دايت فعال لتحقيق الهدف المثالي
•
كيفية إنشاء جدول دايت فعال لتحقيق الهدف المثالي يعتبر إنشاء جدول دايت فعال أمراً مهماً في سبيل تحقيق الهدف المثالي في فقدان الوزن أو بناء العضلات. يعتمد نج…
-

ما هي أفضل طرق لفقدان وزن يصل إلى 35 كيلو؟
•
35 كيلو من الوزن يعتبر تحدياً كبيراً للكثير من الأشخاص الذين يسعون للحصول على وزن مثالي وصحي. وفقدان هذا الكم الكبير من الوزن يتطلب جهداً كبيراً واستراتيجي…
-

فوائد وأضرار رجيم الكربوهيدرات: دليل شامل للرجيم
•
رجيم الكربوهيدرات يعتبر أحد الأنظمة الغذائية الشهيرة والمثيرة للجدل في عالم التغذية، حيث يقوم بتقليل استهلاك الكربوهيدرات وزيادة البروتينات والدهون. ولكن م…
-

جدول لانقاص الوزن: أفضل الطرق لفقدان الوزن بصحة وسرعة
•
جدول لانقاص الوزن: أفضل الطرق لفقدان الوزن بصحة وسرعة يعد الوزن الزائد من المشاكل الصحية التي تواجه الكثير من الناس في العصر الحالي، ويبحث الكثيرون عن أفض…
-

أفضل منتجات للرجيم لتحقيق أهدافك الصحية
•
منتجات للرجيم تعتبر أساسية في تحقيق أهداف الرجيم والحفاظ على الصحة العامة. فقد يكون من الصعب على الكثير منا تحديد الخيارات الصحية والمناسبة لنظام غذائي صحي…
-
تجربتي مع نظام دايت لمدة شهر: التحديات والنتائج
•
تجربتي مع نظام دايت لمدة شهر: التحديات والنتائج تعتبر تجربة اتباع نظام دايت لمدة شهر تحديًا كبيرًا للكثير من الأشخاص الذين يسعون للحفاظ على وزنهم وتحسين ص…
-

فوائد الفول السوداني الكيتو: ذلك الغذاء الصحي المثالي
•
فوائد الفول السوداني الكيتو: ذلك الغذاء الصحي المثالي الفول السوداني الكيتو يعتبر من أهم الأطعمة التي تعتمد عليها نظام الكيتو دايت، حيث يحتوي على العديد م…
-

أفضل طرق للوصول إلى أسرع رجيم في أسبوع
•
البحث عن أسرع رجيم في أسبوع يعتبر من أكثر المواضيع شيوعاً في عالم التغذية والرشاقة. فالكثير من الناس يسعون للحصول على جسم مثالي في وقت قصير وبدون مجهود كبي…
-

أفضل برنامج دايت لتحقيق النتائج المثالية في فترة زمنية قصيرة
•
أفضل برنامج دايت لتحقيق النتائج المثالية في فترة زمنية قصيرة إذا كنت تبحث عن أفضل برنامج دايت لتحقيق النتائج المثالية في فترة زمنية قصيرة، فإنك قد وصلت إل…
-

نظام سريع وفعال لخسارة الوزن بدون تعب
•
نظام سريع وفعال لخسارة الوزن بدون تعب: مع تزايد الوعي بأهمية الصحة واللياقة البدنية، أصبح البحث عن طرق فعالة لفقدان الوزن والحفاظ على الوزن المثالي أمراً م…
-

خطة دايت لمدة شهر: كيف تخسر وزنك بشكل صحي وفعال
•
إذا كنت تبحث عن طريقة صحية وفعالة لخسارة الوزن، فإن خطة دايت لمدة شهر قد تكون الحل الأمثل بالنسبة لك. تحقيق الوزن المثالي يتطلب التزامًا بنظام غذائي متوازن…
-

جدول رجيم لمدة شهر: خطوات لإتباع نظام غذائي صحي
•
جدول رجيم لمدة شهر: خطوات لإتباع نظام غذائي صحي يعتبر الحفاظ على وزن صحي ومواجهة مشكلات السمنة أمرًا هامًا للكثيرين، ولذلك يلجأ الكثير من الأشخاص إلى اتبا…
-

أفضل استراتيجيات الدايت لتخفيف الدهون بصحة
•
أفضل دايت لخسارة الدهون: استراتيجيات فعالة لتحقيق الهدف تعد مشكلة زيادة الوزن وتراكم الدهون من أبرز التحديات التي تواجه الكثير من الأشخاص في يومنا هذا، ولذ…
-

الفواكه الممنوعة في الكيتو دايت: هل تؤثر على عملية الحرق الدهون؟
•
الفواكه الممنوعة في الكيتو دايت: هل تؤثر على عملية الحرق الدهون؟ تعتبر الفواكه من الأطعمة الصحية والمغذية التي يفضل تناولها في العديد من الحميات الغذائية،…
-

أفضل أنظمة غذائية للتخسيس والحفاظ على الوزن المثالي
•
انظمة غذائية للتخسيس أصبحت من أكثر الأمور التي تشغل بال الكثيرين في هذه الأيام، فمع تزايد مشاكل الوزن الزائد والسمنة، أصبح البحث عن أفضل الطرق لفقدان الوزن…
-

فوائد كمية الخضار في الكيتو: دورها في تحقيق النجاح في النظام الغذائي الكيتوني
•
تعتبر كمية الخضار في الكيتو أمرًا مهمًا جدًا في تحقيق النجاح في النظام الغذائي الكيتوني. فالخضار تلعب دورًا حاسمًا في تزويد الجسم بالعناصر الغذائية اللازمة…
-

جدول وجبات رجيم لتحقيق الهدف الصحي بطريقة متوازنة وفعالة
•
جدول وجبات رجيم تُعتبر الريجيمات الغذائية من أكثر الطرق شيوعًا لتحقيق الهدف الصحي، فهي تقدم خطة غذائية محددة لتحقيق فقدان الوزن أو الحفاظ على الوزن بطريقة…
-

برنامج أسبوعي لتناول الطعام الصحي للتخلص من الوزن الزائد
•
برنامج اكل صحي لانقاص الوزن هو برنامج أسبوعي مخصص لتناول الطعام الصحي والمتوازن، بهدف التخلص من الوزن الزائد وتحقيق الوزن المثالي. يهدف هذا البرنامج إلى تو…
-

فوائد الموز في نظام الكيتو: تأثيره على الصحة والتغذية
•
يعتبر النظام الكيتوني واحداً من أشهر الأنظمة الغذائية التي تحظى بشعبية كبيرة في الوقت الحالي. يقوم هذا النظام على تقليل استهلاك الكربوهيدرات وزيادة استهلاك…
-

كيتو كلاسيك جدول: دليلك الشامل للتغذية وجدول الطعام
•
كيتو كلاسيك جدول: دليلك الشامل للتغذية وجدول الطعام تعتبر الحمية الكيتونية واحدة من أكثر الاتجاهات الغذائية شيوعاً في الوقت الحاضر، حيث يعتمد على تقليل كمي…
-

فوائد وأضرار الكيتو الكلاسيكي: دليل شامل لفهم التغذية القليلة الكربوهيدرات
•
إن التغذية القليلة الكربوهيدرات قد أصبحت محور اهتمام الكثيرين في السنوات الأخيرة، ومن بين النظم الغذائية القليلة الكربوهيدرات يأتي الكيتو الكلاسيكي كواحد م…
-

فوائد نظام الكيتو جينك للصحة والعافية
•
نظام الكيتو جينك هو نظام غذائي يعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون الصحية والبروتينات. يعتبر هذا النظام من الأنظمة الغذائية الشهيرة التي…
-

فوائد الكيتو لصحة القلب: دراسة واحدة شاملة
•
فوائد الكيتو لصحة القلب: دراسة واحدة شاملة تعتبر تغذية الكيتو واحدة من الاتجاهات الغذائية الشهيرة التي تتمحور حول تقليل الكربوهيدرات وزيادة الدهون الصحية…
-

شرب الماء في الكيتو: الأهمية والكميات الموصى بها
•
شرب الماء في الكيتو: الأهمية والكميات الموصى بها يعد شرب الماء من أهم العوامل التي يجب أخذها في الاعتبار أثناء اتباع نظام الكيتو. فالماء له دور كبير في دع…
-

الدايت: طريقة فعالة لخسارة الوزن والحفاظ على الصحة
•
الدايت: طريقة فعالة لخسارة الوزن والحفاظ على الصحة تعتبر الدايت واحدة من أكثر الطرق فعالية لخسارة الوزن والحفاظ على الصحة. إن كلمة “دايت” تعني نقصان الوزن…
-

طرق فعالة لخسارة الوزن في أسبوع
•
خسارة الوزن في أسبوع هي مهمة تحتاج إلى جهد واستعداد لتغيير نمط حياة الشخص. يبحث العديد من الأشخاص عن طرق فعالة لتحقيق هذا الهدف في وقت قصير. في هذا المقال،…
-

أشهى الوصفات: أطباق كيتو مسموحة ولذيذة
•
اكلات مسموحة بالكيتو إذا كنت من محبي الطعام الصحي وتبحث عن وصفات لذيذة ومسموحة في نظام الكيتو، فأنت في المكان المناسب. في هذا المقال سنقدم لكم مجموعة من أ…
-

فوائد وأنواع أطعمة الكيتو لتحقيق الهدف الصحي
•
أطعمة الكيتو (أو النظام الغذائي الكيتوجيني) هي نوع من الأنظمة الغذائية التي تعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون، مما يؤدي إلى دخول الجسم…
-

فوائد وأضرار طعام كيتو: دليل شامل
•
طعام كيتو: دليل شامل تعتبر الحمية الكيتونية أو ما يعرف بالكيتو diet واحدة من أشهر الحميات الغذائية التي انتشرت في الآونة الأخيرة، حيث تعتمد هذه الحمية على…
-

فوائد اطعمه الكيتو وأهميتها في الحمية الغذائية
•
فوائد اطعمه الكيتو وأهميتها في الحمية الغذائية تعتبر اطعمه الكيتو من أهم العناصر التي تستخدم في الحمية الغذائية الكيتونية، والتي تعتمد على تقليل تناول الك…
-

فوائد وجدول اكل دايت لتحقيق الهدف الصحي
•
فوائد وجدول اكل دايت لتحقيق الهدف الصحي تعتبر الدايت أحد الوسائل الفعالة لتحقيق الهدف الصحي والحفاظ على الوزن المثالي. ومن أهم الأدوات التي تساعد في تحقيق…
-

فهم ماهية حمية الكيتو: دليل كامل للمبتدئين
•
ماهي حمية الكيتو: دليل كامل للمبتدئين حمية الكيتو أو الكيتوجينيك هي نوع من الحميات الغذائية التي تعتمد على تقليل استهلاك الكربوهيدرات وزيادة استهلاك الدهو…
-

فوائد وآثار نظام الكيتو على الصحة والجسم
•
ريجيم الكيتو أصبح من أحدث الاتجاهات الغذائية التي أثارت اهتمام الكثيرين في الآونة الأخيرة، حيث يعتمد هذا النظام الغذائي على تقليل تناول الكربوهيدرات وزيادة…
-

فوائد وتأثيرات أكل الكيتو على الصحة
•
مقدمة: فوائد وتأثيرات أكل الكيتو على الصحة يعتبر أكل الكيتو من أحد التوجهات الغذائية الشهيرة في الآونة الأخيرة, حيث أنه يعد نظاماً غذائياً يقلل من استهلاك…
-

دليل كيتو دايت PDF: كل ما تحتاج معرفته لبدء الحمية الكيتونية
•
الكيتو دايت pdf هو دليل شامل يحتوي على كل المعلومات التي تحتاجها لبدء الحمية الكيتونية. تعتبر الحمية الكيتونية واحدة من أكثر الحميات شعبية في الوقت الحالي،…
-

نظام كيتو: اقوى نظام غذائي لتحقيق اللياقة وفقدان الوزن
•
نظام كيتو: اقوى نظام غذائي لتحقيق اللياقة وفقدان الوزن إذا كنت تبحث عن طريقة فعالة لتحسين لياقتك وفقدان الوزن بشكل سريع وصحي، فإن نظام كيتو يمكن أن يكون ا…
-

فوائد وأسرار اكلات نظام الكيتو للصحة والعافية
•
اكلات نظام الكيتو هي واحدة من أحدث الاتجاهات في عالم النظام الغذائي والتغذية، والتي تستهدف تحويل جسمك إلى آلة حرق دهون فعالة. يعتمد هذا النظام على تقليل تن…
-

نظام كيتو الاقتصادي: الطريق نحو الاستقرار الاقتصادي والتنمية المستدامة
•
نظام كيتو الاقتصادي: الطريق نحو الاستقرار الاقتصادي والتنمية المستدامة تعتبر الاقتصادات العالمية معرضة للعديد من التحديات والصعوبات التي تؤثر على استقراره…
-

جدول نظام الكيتو في رمضان: كيف تحافظ على الصحة خلال الصيام؟
•
جدول نظام الكيتو في رمضان: كيف تحافظ على الصحة خلال الصيام؟ تعتبر الصيام خلال شهر رمضان من أهم العبادات الإسلامية ولكن في بعض الأحيان يمكن أن يؤثر الصيام…
-

فوائد نظام الكيتو للصحة والعافية
•
اي هو نظام الكيتو هو نظام غذائي يعتمد على تناول كميات منخفضة من الكربوهيدرات وكميات عالية من الدهون، مما يؤدي إلى دخول الجسم في حالة تسمى “الكيتوز” حيث يبد…
-

كل ما تحتاج لمعرفته عن دايت الكيتو: فوائد وتأثيرات جانبية
•
ماهو دايت الكيتو؟ دايت الكيتو أو النظام الغذائي الكيتوجيني هو نوع من الحميات الغذائية التي تعتمد على تناول كميات قليلة من الكربوهيدرات وكميات عالية من الده…
-

جدول أسبوعي للكيتو دايت: خطة غذائية متوازنة للحفاظ على اللياقة
•
جدول أسبوعي للكيتو دايت: خطة غذائية متوازنة للحفاظ على اللياقة تُعتبر الكيتو دايت واحدة من أشهر النظم الغذائية التي انتشرت عالمياً في السنوات الأخيرة، حيث…
-

فوائد وتجربة برنامج غذائي كيتو لمدة اسبوع
•
فوائد وتجربة برنامج غذائي كيتو لمدة اسبوع يعتبر برنامج غذائي كيتو لمدة اسبوع من البرامج الغذائية التي انتشرت بشكل كبير في الآونة الأخيرة، حيث يعتمد هذا ال…
-

فطور كيتو للمبتدئين: 5 وصفات صحية وسهلة لبداية يومك بطاقة ونشاط
•
في بداية يومنا، نحتاج إلى وجبة فطور تمدنا بالطاقة والنشاط لنستعد ليوم حافل بالأنشطة والتحديات. ولذلك، يعتبر فطور كيتو للمبتدئين خيارًا مثاليًا للحفاظ على ت…
-

فوائد وأسرار نظام الكيتو الصحي
•
نظام الكيتو الصحي هو نظام غذائي يعتمد على تقليل تناول الكربوهيدرات وزيادة استهلاك الدهون الصحية والبروتينات. يهدف هذا النظام إلى دخول الجسم في حالة الكيتوز…
-

فوائد وجدول طعام الكيتو: كيف يمكن تنظيم وجباتك بشكل فعال؟
•
جدول اكل الكيتو: فوائد وكيفية تنظيم وجباتك بشكل فعال يعتبر الكيتو من أحدث الاتجاهات في عالم الحمية الغذائية، حيث يركز على تقليل تناول الكربوهيدرات وزيادة…
-

طريقة عمل رجيم الكيتو: دليل شامل للبدء
•
طريقة عمل رجيم الكيتو: دليل شامل للبدء إذا كنت تبحث عن طريقة فعالة لفقدان الوزن وتحسين صحتك بشكل عام، فقد وصلت إلى المكان الصحيح. في هذا الدليل، سنقدم لك…
-
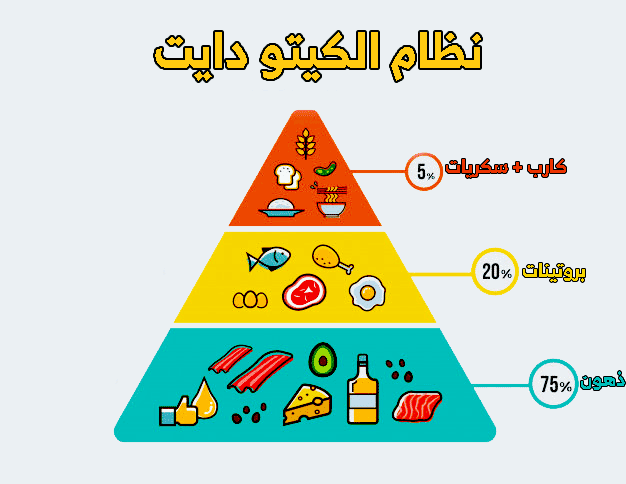
فوائد وعيوب انظمة كيتو دايت: دليل كامل
•
انظمة كيتو دايت هي نوع من الأنظمة الغذائية التي اكتسبت شعبية كبيرة في السنوات الأخيرة بسبب فوائدها المحتملة في فقدان الوزن وتحسين الصحة العامة. تعتمد هذه ا…
-

جدول رجيم كيتو: دليلك الشامل لتحقيق النتائج المثالية
•
جدول رجيم كيتو: دليلك الشامل لتحقيق النتائج المثالية إذا كنت تبحث عن طريقة فعالة لخسارة الوزن وتحسين صحتك بشكل عام، فإن جدول رجيم كيتو يمكن أن يكون الخيار…
-

كيتو دايت: نظام غذائي يحقق فوائد صحية مذهلة
•
كيتو دايت نظام غذائي يثير اهتمام الكثيرين في الوقت الحالي، نظراً لفوائده الصحية المذهلة. يعتمد هذا النظام على تقليل تناول الكربوهيدرات وزيادة تناول الدهون…
-

فوائد وأسرار كيتو كلاسيك الخلابة للصحة والعافية
•
يعتبر كيتو كلاسيك واحداً من أفضل الأنظمة الغذائية القائمة على تقليل استهلاك الكربوهيدرات وزيادة استهلاك الدهون، مما يؤدي إلى دخول الجسم في حالة الكيتوز. تع…
-

جدول دايت لتخفيف الوزن: خطة غذائية متوازنة للحصول على نتائج فعّالة
•
جدول دايت لتخفيف الوزن هو خطة غذائية متوازنة تهدف إلى تحقيق نتائج فعّالة في فقدان الوزن وتحسين الصحة العامة. تعد هذه الخطة الغذائية مناسبة للأشخاص الذين يب…
-

فوائد وأهمية الدايت في رمضان
•
في شهر رمضان المبارك، يلتزم الصائمون بالصيام من الفجر إلى المغرب، ويسعون لتحقيق الصحة الجيدة والوزن المثالي. لذا، تعتبر فوائد وأهمية الدايت في رمضان أمراً…
-

تجربتي مع برنامج دايت لمدة شهر: النتائج والتحديات
•
تجربتي مع برنامج دايت لمدة شهر: النتائج والتحديات يعتبر برنامج دايت لمدة شهر أحد الأساليب الشائعة والمشهورة لفقدان الوزن وتحسين اللياقة البدنية. وقد قررت أ…
-

برنامج تخسيس الوزن: طرق فعالة لفقدان الوزن بسرعة وبشكل صحيح
•
برنامج تخسيس الوزن: طرق فعالة لفقدان الوزن بسرعة وبشكل صحيح يعتبر برنامج تخسيس الوزن أحد الحلول الفعالة للقضاء على الوزن الزائد والحفاظ على الجسم بشكل صحي…
-
برنامج كيتو اسبوعي: دليلك للبدء في نظام الكيتو الغذائي
•
برنامج كيتو الأسبوعي هو دليلك الشامل للبدء في نظام الكيتو الغذائي، حيث يقدم لك خطة غذائية متكاملة تساعدك على الالتزام بنظام غذائي صحي وفعال. يهدف هذا البرن…
-

تجربتي مع رجيم الكيتو في أسبوع: تحديات ونتائج
•
تجربتي مع رجيم الكيتو في أسبوع: تحديات ونتائج رجيم الكيتو في أسبوع تجربتي كانت تجربة مثيرة ومحفوفة بالتحديات والنجاحات. فقد قررت أخيرًا الانضمام للعديد من…
-

تجربتي مع نظام كيتو دايت لمدة شهر: فوائد وتحديات
•
نظام كيتو دايت لمدة شهر: فوائد وتحديات يعتبر نظام كيتو دايت واحداً من أشهر الأنظمة الغذائية التي اكتسبت شهرة كبيرة في السنوات الأخيرة. وقد قررت أن أجرب هذ…
-

نظام صحي لخسارة الوزن: الطرق المبتكرة لتحقيق النتائج المرجوة
•
نظام صحي لخسارة الوزن: الطرق المبتكرة لتحقيق النتائج المرجوة تعتبر مشكلة الوزن الزائد والسمنة من أكثر المشاكل الصحية انتشاراً في العصر الحالي. ولذلك، يبحث…
-

نظام غذائي صحي للحفاظ على الوزن
•
نظام غذائي صحي لانقاص الوزن هو أحد العناصر الأساسية التي يجب أخذها بعين الاعتبار للحفاظ على صحة الجسم والوزن المثالي. فبفضل تناول الطعام الصحي والمتوازن يم…
-

أفضل رجيم لانقاص الوزن: الطريقة الفعالة لتحقيق الهدف
•
أفضل رجيم لانقاص الوزن: الطريقة الفعالة لتحقيق الهدف تعتبر فقدان الوزن أمرًا مهمًا للكثير من الأشخاص، ولكن العثور على الطريقة المناسبة لذلك قد يكون تحديًا….
-

تجربتي مع نظام كيتو لمدة أسبوع: تحديات ونتائج
•
تجربتي مع نظام كيتو لمدة أسبوع: تحديات ونتائج نظام كيتو لمدة أسبوع هو تحدي يقوم به الكثيرون لاختبار فوائد وتأثيرات هذا النظام الغذائي على الجسم. قمت بتجرب…
-

برنامج دايت: كيف تحقق أهدافك في خسارة الوزن بنجاح؟
•
برنامج دايت: كيف تحقق أهدافك في خسارة الوزن بنجاح؟ تعتبر خسارة الوزن والحفاظ على وزن صحي من الأهداف الهامة للكثير من الأشخاص. ومع وجود العديد من البرامج و…
-

فهم مفهوم الكيتو وفوائده الصحية
•
ماهو الكيتو؟ يُعتبر الكيتو من الاتجاهات الغذائية الشهيرة في الوقت الحالي، حيث يقترح نظام غذائي يركز على تقليل الكربوهيدرات وزيادة الدهون الصحية والبروتينا…
-

فوائد ونصائح نظام الكيتو الاسبوعي: دليلك لخسارة الوزن بشكل صحي وفعال
•
فوائد ونصائح نظام الكيتو الاسبوعي: دليلك لخسارة الوزن بشكل صحي وفعال يعتبر نظام الكيتو الاسبوعي واحداً من أشهر الأنظمة الغذائية التي تهدف إلى خسارة الوزن…
-

نظام غذائي فعال للتنحيف بشكل صحي وآمن
•
نظام غذائي للتنحيف هو أحد الطرق الفعالة والآمنة لفقدان الوزن وتحسين الصحة العامة. إن أهمية اتباع نظام غذائي صحي ومتوازن للتخلص من الوزن الزائد والدهون الزا…
-

أفضل نظام غذائي لفقدان الوزن بصحة وبسرعة
•
أفضل نظام غذائي لانقاص الوزن هو موضوع يشغل الكثير من الأشخاص الراغبين في خسارة الوزن بصحة وبسرعة. فقد يكون من الصعب اختيار النظام الغذائي المناسب الذي يلبي…
-

وجبات دايت: أفضل الخيارات للتخفيف من الوزن
•
وجبات دايت: أفضل الخيارات للتخفيف من الوزن تعتبر الوجبات الدايت أحد أهم العوامل في عملية التخفيف من الوزن والحفاظ على الصحة. فحسب الكثير من الأبحاث العلمي…
-

نظام غذائي فعال لتخسيس الوزن بشكل صحي
•
نظام غذائي لخسارة الوزن هو أحد الطرق الفعالة والصحية لتقليل الوزن الزائد وتحسين الصحة العامة. يعتمد هذا النظام على تناول الطعام بشكل متوازن وصحيح، مع مراعا…
-

فوائد وآثار نظام غذائي كيتو على الجسم
•
نظام غذائي كيتو قد أصبح من أكثر الأنظمة الغذائية شهرة في الفترة الأخيرة، حيث يعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون الصحية والبروتينات. وقد…
-

نظام غذائي لتحقيق فقدان الوزن بشكل صحي
•
يُعتبر اتباع نظام غذائي لانقاص الوزن أمراً مهماً لكثير من الأشخاص السعيين وراء تحقيق وزن مثالي وصحي. يتطلب ذلك النظام الغذائي الالتزام بتناول الطعام الصحي…
-

فوائد وأسئلة شائعة حول جدول كيتو: دليل كامل
•
جدول كيتو: فوائد وأسئلة شائعة حوله تعتبر الحمية الكيتوجينية من أحدث الاتجاهات الغذائية التي اكتسبت شعبية كبيرة خلال السنوات الأخيرة بفضل فوائدها الصحية الم…
-

نظام الكيتو جدول: دليلك لفقدان الوزن وتحسين الصحة بطريقة صحية
•
نظام الكيتو جدول: دليلك لفقدان الوزن وتحسين الصحة بطريقة صحية يعتبر نظام الكيتو جدول من النظم الغذائية الشهيرة التي تهدف إلى تحفيز عملية حرق الدهون في الجس…
-

فوائد منتجات كيتو في تحقيق الهدف الغذائي والصحي
•
مقدمة: منتجات كيتو تعتبر خياراً ممتازاً لتحقيق الهدف الغذائي والصحي للأشخاص الذين يتبعون نظام غذائي كيتوجيني. فهذه المنتجات تحتوي على مكونات تساعد في تحفي…
-

فوائد وأضرار برنامج الكيتو: دليل كامل للمبتدئين
•
برنامج الكيتو: دليل كامل للمبتدئين في تحقيق أهدافهم الصحية برنامج الكيتو هو نظام غذائي يعتمد على تناول كميات منخفضة من الكربوهيدرات وكميات عالية من الدهون…
-

فوائد وآثار نظام الكيتو دايت على الصحة
•
نظام الكيتو دايت هو نظام غذائي يعتمد على تقليل تناول الكربوهيدرات وزيادة تناول الدهون الصحية والبروتينات. يعتمد هذا النظام على دفع الجسم للإنتقال من حرق ال…
-

فوائد وتحديات اتباع رجيم الكيتو للحصول على الوزن المثالي
•
رجيم الكيتو أصبح من أشهر الأنظمة الغذائية التي يتبعها الكثير من الأشخاص في سبيل خسارة الوزن والوصول إلى الجسم المثالي. وتعتمد فكرة هذا النظام الغذائي على ت…
-

كيتو دايت: فوائد وأضرار هذه النظام الغذائي المثير للجدل
•
تعتبر كيتو دايت واحدة من الأنظمة الغذائية التي أثارت الكثير من الجدل في الآونة الأخيرة. تتميز هذه النظام الغذائي بتقليل كمية الكربوهيدرات المستهلكة وزيادة…
-

فوائد اتباع نظام غذائي محسوب السعرات لصحة الجسم
•
نظام غذائي محسوب السعرات يعتبر أحد النظم الغذائية الهامة التي تهدف إلى الحفاظ على صحة الجسم وضبط الوزن بشكل فعال. يعتمد هذا النظام على حساب عدد السعرات الح…
-

برنامج نظام غذائي لانقاص الوزن: الطريقة الفعالة لتحقيق الهدف
•
برنامج نظام غذائي لانقاص الوزن: الطريقة الفعالة لتحقيق الهدف إذا كنت تبحث عن الطريقة الفعالة لانقاص الوزن والحفاظ على وزنك المثالي، فإن برنامج نظام غذائي…
-

أهمية اتباع نظام غذائي لانقاص الوزن بشكل صحي
•
مقدمة أصبحت مشكلة الوزن الزائد من أكبر المشاكل التي تواجه الكثير من الأشخاص في العصر الحديث، حيث تؤثر بشكل مباشر على صحة الإنسان وجودته في الحياة. لذا، يعت…
-

نظام كيتو دايت: دليلك المجاني لفقدان الوزن وتحسين الصحة
•
نظام كيتو دايت: دليلك المجاني لفقدان الوزن وتحسين الصحة نظام كيتو دايت مجانا يُعتبر نظام كيتو دايت واحداً من أكثر الأنظمة الغذائية شهرة في الوقت الحالي،…
-

الحمية الغذائية المثالية لتخفيف الوزن
•
أفضل دايت لخسارة الوزن تعتبر الحمية الغذائية المثالية لتخفيف الوزن أمرًا مهمًا للعديد من الأشخاص الذين يسعون إلى تحقيق الوزن المثالي والحفاظ على صحتهم العا…
-

فوائد طعام تخسيس في تحقيق الوزن المثالي
•
تعد فوائد طعام تخسيس من أهم الطرق الصحية لتحقيق الوزن المثالي والحفاظ عليه، حيث يساعد هذا النوع من الأطعمة في تقليل الدهون والسعرات الحرارية بالجسم وتحفيز…
-
مقويات الطفولة: كيف تساهم في تطوير الأطفال
•
مقويات الطفولة: كيف تساهم في تطوير الأطفال مقويات الطفولة هي العوامل والظروف التي تساهم في تحسين نمو وتطور الأطفال. فهي تعتبر أساساً أساسياً في بناء شخصية…
-

فوائد وأضرار دواء المقوي العام: كل ما تحتاج لمعرفته
•
دواء المقوي العام هو أحد الأدوية الشائعة التي يتم استخدامها لتحسين الصحة العامة للجسم وتعزيز القدرة على مكافحة الأمراض والإصابات. يعتبر هذا الدواء مهماً جد…
-
الاعراض الجانبية للاستخدام المفرط للفيتامينات
•
الاعراض الجانبية للفيتامينات يعتبر تناول الفيتامينات ضرورياً لصحة الجسم والحفاظ على الوظائف الحيوية، ولكن استخدامها بشكل مفرط قد يؤدي إلى ظهور العديد من ا…
-

أهمية الرياضة في الحفاظ على القوام المثالي والصحة الجسدية
•
تعتبر الرياضة من العوامل الأساسية في الحفاظ على القوام المثالي والصحة الجسدية. فممارسة الرياضة بانتظام تلعب دوراً كبيراً في الحفاظ على اللياقة البدنية والو…
-
افضل مكمل غذائي حبوب: كيف تختار المكمل الغذائي المناسب لصحتك؟
•
اقتناء أفضل مكمل غذائي حبوب يمكن أن يكون تحديًا، خاصة مع وجود العديد من الخيارات المتاحة في السوق. فالاختيار الصحيح لمكمل غذائي مهم للحفاظ على صحتك وزيادة…
-

فوائد وأضرار مكملات غذائية للكبار: دليل شامل
•
مكملات غذائية للكبار تعتبر من المواضيع المثيرة للاهتمام في عالم الصحة والتغذية في الوقت الحالي، حيث يتساءل الكثيرون عن فوائدها وأضرارها على الصحة. وتهدف هذ…
-
فوائد وأهمية استخدام المكملات الغذائية الصحية
•
مكمل غذائي صحي هو عنصر غذائي يتم تناوله إلى جانب الوجبات الرئيسية لتعويض أي نقص في العناصر الغذائية الأساسية. تعد المكملات الغذائية الصحية ذات أهمية كبيرة…
-

فوائد واستخدامات كبسولات مقويات لتعزيز الصحة العامة
•
كبسولات مقويات هي منتجات طبيعية تستخدم لتعزيز الصحة العامة وزيادة مستوى الطاقة والحيوية. تعتبر هذه الكبسولات من الوسائل الفعالة التي تساعد على تعزيز الجهاز…
-
زيادة الطول بسرعة: أسرار تخلصك من القصر في وقت قياسي
•
وصفة لزيادة الطول بسرعة يعتبر الطول من الصفات الجمالية التي تهم الكثيرين، فهو يعكس القوة والثقة ويساعد في التأثير الإيجابي على الآخرين. ولذلك، يسعى الكثير…
-

فوائد وأضرار استخدام أقراص فيتامين
•
فوائد وأضرار استخدام أقراص فيتامين يعتبر استخدام الأقراص الغذائية المحتوية على فيتامينات من الطرق الفعالة لتعويض نقص الفيتامينات في الجسم وتعزيز الصحة الع…
-
أفضل ملتي فيتامين للاطفال في مصر: كيف تختار الفيتامين المناسب لطفلك؟
•
أفضل ملتي فيتامين للاطفال في مصر: كيف تختار الفيتامين المناسب لطفلك؟ فيتامينات الأطفال تعتبر من أهم العناصر الغذائية التي يحتاجها الأطفال لتقوية جهاز المن…
-

تأثير فيتامين للاطفال في فتح الشهية وتعزيز النمو الصحي
•
فيتامين للاطفال فاتح شهية هو عامل مهم في دعم نمو الأطفال وتعزيز صحتهم العامة. يعتبر هذا الفيتامين أحد العناصر الغذائية الرئيسية التي تؤثر على فتح الشهية لد…
-
زيادة الطول في سن 18: الأسرار والطرق المثلى للنمو
•
زيادة الطول في سن 18: الأسرار والطرق المثلى للنمو يعتبر الطول من العوامل الجمالية المهمة في حياة الإنسان، فهو يلعب دوراً هاماً في شكل الجسم وثقته بنفسه. و…
-

فوائد ملتي فيتامين شراب ودوره في تعزيز الصحة
•
ملتي فيتامين شراب هو منتج يحتوي على مجموعة متنوعة من الفيتامينات والمعادن الضرورية لصحة الجسم. يُعتبر هذا الشراب مصدراً غنياً بالمغذيات التي تلعب دوراً هام…
-
مكمل غذائي يحتوي على كل الفيتامينات: الأهمية والفوائد المحتملة
•
مكمل غذائي يحتوي على كل الفيتامينات: الأهمية والفوائد المحتملة يعتبر تناول مكمل غذائي يحتوي على كل الفيتامينات أمراً ضرورياً للحفاظ على صحة الجسم وضمان تو…
-

فوائد فيتامين الاسترس الذي يساعد على تحسين التركيز للأطفال
•
فوائد فيتامين الاسترس في تحسين التركيز للأطفال فيتامين الاسترس يعد من الفيتامينات الهامة لصحة الإنسان، ويتمتع بفوائد عديدة للجسم والعقل. واحدة من أهم فوائد…
-
أفضل شراب ملتي فيتامين للاطفال: تعزيز صحة الطفل بشكل متكامل
•
أفضل ملتي فيتامين للاطفال شراب يعتبر من العناصر الأساسية التي يحتاجها الطفل لتعزيز صحته ونموه بشكل سليم. فالطفولة هي مرحلة حيوية في حياة الإنسان، وتحتاج ال…
-

مراجعة افضل ادوية المكملات الغذائية لتحسين الصحة واللياقة
•
مراجعة افضل ادوية المكملات الغذائية لتحسين الصحة واللياقة إذا كنت تبحث عن طرق لتحسين صحتك وزيادة لياقتك البدنية، فإن المكملات الغذائية قد تكون الحل الأمثل…
-
أحسن فيتامين للاطفال: كيف تختار الفيتامين المناسب لصحة طفلك؟
•
أحسن فيتامين للاطفال: كيف تختار الفيتامين المناسب لصحة طفلك؟ الفيتامينات والمعادن الضرورية لنمو وتطور الأطفال لها دور مهم في الحفاظ على صحتهم ونشاطهم اليوم…
-

فوائد وأهمية استخدام مكمل غذائي لزيادة الوزن للأطفال
•
مكمل غذائي لزيادة الوزن للأطفال هو أحد الحلول التي تعتمد عليها العديد من الأسر لمساعدة أطفالهم على زيادة وزنهم بشكل صحي وآمن. يعاني العديد من الأطفال من نق…
-
فوائد وأسماء فيتامينات للأطفال وأهميتها في النمو الصحي
•
فيتامينات للأطفال هي مجموعة من العناصر الغذائية الأساسية التي تلعب دوراً هاماً في نمو وتطور الطفل. توفر هذه الفيتامينات العديد من الفوائد الصحية والغذائية…
-

أهمية استخدام الأدوية الفيتامينية والمعدنية في الحفاظ على الصحة
•
أدوية الفيتامينات والمعادن هي من أهم العوامل التي تساهم في الحفاظ على الصحة والعافية. فالجسم بحاجة مستمرة لتلك العناصر الغذائية لضمان وظائفه المختلفة. ومن…
-
فوائد فيتامينات شراب للكبار وأهميتها للصحة
•
فوائد فيتامينات شراب للكبار تعتبر فيتامينات شراب للكبار أحد الوسائل الفعالة لتعزيز صحة الإنسان والحفاظ على قوته ونشاطه. حيث تحتوي هذه الفيتامينات على مجموع…
-

فوائد وأهمية تناول فيتامين للاطفال
•
يعتبر تناول فيتامين للاطفال أمراً مهماً لضمان نمو وتطور صحي للأطفال. فالفيتامينات تلعب دوراً أساسياً في دعم النظام المناعي وتحفيز النمو الطبيعي والصحي. إذا…
-
فوائد فيتامين د كدواء أساسي للصحة والعلاج
•
فيتامين دواء هام جداً للحفاظ على صحة الجسم وعلاج العديد من الأمراض والمشاكل الصحية. يُعتبر فيتامين د واحداً من الفيتامينات الضرورية التي يحتاجها الإنسان لل…
-

فوائد وأهمية المكمل الغذائي لعمر ١٢ عامًا
•
تعتبر فوائد وأهمية المكمل الغذائي لعمر ١٢ عامًا من الأمور التي يجب أخذها بعين الاعتبار لضمان النمو والتطور الصحيح للجسم في هذه المرحلة العمرية الحرجة. يعتب…
-
فوائد دواء فيتامين لصحة الجسم
•
في هذا العصر الحديث، أصبح الوعي بأهمية الرعاية الصحية وتناول الفيتامينات أمرًا أساسيًا للحفاظ على صحة الجسم. إن دواء فيتامين يعد أحد الوسائل الفعالة والضرو…
-

الملتي فيتامين للاطفال: شراب مهم لتعزيز صحة الصغار
•
شراب الملتي فيتامين للاطفال هو منتج مهم يساعد في تعزيز صحة الصغار وتغذيتهم بالفيتامينات والمعادن الضرورية. يعد هذا الشراب وسيلة فعالة لتلبية احتياجات الأطف…
-
أفضل أكلات لزيادة الطول بشكل طبيعي وصحي
•
أكلات تساعد على زيادة الطول تعتبر زيادة الطول من الأمور التي يبحث عنها الكثيرون، فالطول يعتبر عاملا مهما في الجاذبية الشخصية والثقة بالنفس. ولكن ما لا يعرف…
-

فوائد حبوب فيتامين للاطفال وكيفية استخدامها بشكل آمن
•
تعتبر حبوب فيتامين للاطفال أحد العناصر الغذائية الهامة التي يحتاجها الأطفال لتعزيز نموهم وتطورهم الصحي. وتحتوي هذه الحبوب على العديد من الفيتامينات والمعاد…
-
فوائد فيتامين شراب للكبار وكيفية استخدامه بشكل صحيح
•
فوائد فيتامين شراب للكبار وكيفية استخدامه بشكل صحيح يعتبر فيتامين شراب للكبار أحد الإضافات الغذائية الهامة التي تعزز صحة الجسم وتساهم في تعزيز الجهاز المن…
-

فوائد الزنك لزيادة الطول: كيف يساعد الزنك في تحسين النمو والطول؟
•
فوائد الزنك للطول تعتبر الفوائد الصحية للزنك متعددة ومتنوعة، ومن بين هذه الفوائد تأثيره الإيجابي في زيادة الطول وتحسين عملية النمو. فالزنك عنصر غذائي مهم ل…
-
فوائد وأضرار حبوب زيادة الطول بعد البلوغ
•
تعتبر حبوب لزيادة الطول بعد البلوغ منتجات مثيرة للاهتمام للكثير من الأشخاص الذين يرغبون في زيادة ارتفاعهم بعد بلوغهم. فهناك العديد من الفوائد والأضرار المح…
-

فوائد فيتامين جروميجا لصحة الجسم والعقل
•
إن فيتامين جروميجا هو أحد الفيتامينات الضرورية لصحة الجسم والعقل، ويحتوي على العديد من الفوائد الهامة للإنسان. يعتبر فيتامين جروميجا من العناصر الغذائية ال…
-
شراب مقويات للاطفال: الحل الصحي والآمن لتعزيز نموهم
•
شراب مقويات للاطفال: الحل الصحي والآمن لتعزيز نموهم تعتبر مقويات الطفل السائلة والسيروبات أدوية تساعد في تعزيز صحة الأطفال وتقوية جسمهم بشكل طبيعي. ويعتبر…
-

فوائد وأضرار تناول فيتامينات الشراب: دليل شامل
•
فيتامين شراب يُعتبر من المكملات الغذائية الهامة التي يمكن أن تكون ضرورية لبعض الأشخاص. فهي توفر للجسم العديد من العناصر الغذائية الضرورية لصحة الإنسان. ومع…
-
فوائد الأرجنين وتأثيره على هرمون النمو
•
الأرجنين وهرمون النمو من المواضيع الهامة التي تشغل بال الكثير من الأشخاص، فالأرجنين هو حمض أميني أساسي يلعب دوراً هاماً في عدة وظائف حيوية في الجسم، بينما…
-

التركيز والفوائد: فيتامين التركيز لتحسين تركيز الأطفال
•
فيتامين التركيز للاطفال هو موضوع مهم يهم الكثير من الأهل والمربين حيث يسعون لتحسين تركيز الأطفال وزيادة قدرتهم على التركيز والانتباه. يعتبر فيتامين التركيز…
-
فوائد فيتامينات لزيادة الطول بطريقة طبيعية
•
فوائد فيتامينات لزيادة الطول بطريقة طبيعية تعد الفيتامينات من العناصر الغذائية الضرورية التي تلعب دورًا مهمًا في دعم وتعزيز الصحة العامة للجسم. ومن بين هذ…
-

تأثير مشروب زيادة الطول على نمو الجسم وارتفاع القامة
•
مشروب زيادة الطول هو موضوع يثير اهتمام الكثير من الأشخاص الذين يرغبون في زيادة ارتفاعهم وتحسين قامتهم. يعتقد الكثيرون أن هذا المشروب قد يساهم في تعزيز نمو…
-
فوائد أفضل مكمل غذائي بفيتامينات ومعادن لصحة متوازنة
•
أفضل مكمل غذائي فيتامينات ومعادن يعتبر أحد أهم العناصر التي تساهم في الحفاظ على صحة الجسم والعقل. فالجسم بحاجة إلى توازن مثالي من الفيتامينات والمعادن ليعم…
-

فوائد دواء ارجنين للاطفال وطرق استخدامه الصحيحة
•
فوائد دواء ارجنين للاطفال وطرق استخدامه الصحيحة يُعتبر دواء ارجنين من الأدوية الهامة التي يمكن استخدامها لعلاج العديد من الأمراض والحالات الصحية لدى الأطف…
-
فوائد دواء الطول و كيفية استخدامه
•
فوائد دواء الطول و كيفية استخدامه يعتبر دواء الطول أحد العقاقير الطبية التي تستخدم لزيادة طول الجسم وتحسين نمو العظام. يُستخدم هذا الدواء عادةً لدى الأطفا…
-

فوائد فيتامينات تحفز هرمون النمو وأهميتها للجسم
•
تُعتبر الفيتامينات التي تحفز هرمون النمو أحد العناصر الغذائية الضرورية لدعم نمو وتطور الجسم. فهذه الفيتامينات تلعب دوراً حيوياً في تنشيط هرمون النمو الذي ي…
-
تجربتي مع حبوب زيادة الطول: حقيقة أم خيال؟
•
تجربتي مع حبوب زيادة الطول: حقيقة أم خيال؟ تعد زيادة الطول أمرًا يثير اهتمام الكثيرين، خاصة في المجتمعات التي تعتبر الطول عاملًا مهمًا في جمال الشخص وثقته…
-

فوائد المكملات الغذائية التي تحتوي على جميع الفيتامينات
•
مكمل غذائي يحتوي على جميع الفيتامينات هو منتج يعتمد عليه الكثيرون لتحسين صحتهم وزيادة مستويات الطاقة وتعزيز وظائف الجسم. تعتبر المكملات الغذائية التي تحتوي…
-
فوائد ومخاطر استخدام حبوب هرمون النمو لزيادة الطول للبالغين
•
فوائد ومخاطر استخدام حبوب هرمون النمو لزيادة الطول للبالغين تعتبر حبوب هرمون النمو وسيلة شائعة لزيادة الطول لدى البالغين الذين يرغبون في زيادة طولهم. يُعت…
-

كيفية اختيار أفضل مكمل غذائي للأطفال لزيادة الوزن والطول؟
•
يُعتبر اختيار أفضل مكمل غذائي للأطفال لزيادة الوزن والطول أمرًا مهمًا لتحسين صحة الأطفال وضمان نموهم السليم. فمن المهم جدًا أن يحصل الأطفال على الغذاء الكا…
-
فوائد فيتامين ارجيفيت وأهميته لصحة الجسم
•
فوائد فيتامين ارجيفيت وأهميته لصحة الجسم إن فيتامين ارجيفيت (أو فيتامين A) من الفيتامينات الضرورية لصحة الإنسان، حيث يلعب دوراً هاماً في دعم وظائف الجسم ا…
-

فوائد ومخاطر استخدام حبوب الطول: دليل شامل
•
تعد حبوب الطول من المواضيع التي تثير الكثير من الجدل والاهتمام في مجتمعنا اليوم. فهي تشكل مصدر قلق للكثير من الأشخاص الذين يرغبون في زيادة طولهم بشكل سريع…
-
فوائد ومخاطر استخدام حبوب لزيادة الطول: الحقيقة والأساطير
•
الحقيقة والأساطير حول حبوب لزيادة الطول: فوائد ومخاطر الاستخدام تعتبر زيادة الطول محل اهتمام كبير لدى الكثير من الأشخاص، وقد يلجأ بعضهم إلى استخدام الحبوب…
-

علاج Focus: طرق فعالة لزيادة الطول
•
علاج Focus: طرق فعالة لزيادة الطول يعتبر الطول أحد العوامل الجذابة والمهمة في حياة الإنسان، وقد يبحث العديد من الأشخاص عن طرق فعالة لزيادة طولهم. يعد علاج…
-
أرجيفيت فوكس: روح الاستكشاف والمغامرة
•
أرجيفيت فوكس: روح الاستكشاف والمغامرة أرجيفيت فوكس يعتبر أحد أهم رواد الاستكشاف والمغامرة في التاريخ الحديث، فهو شخصية ملهمة تحمل بداخلها شغفاً لا حدود له…
-

حبوب لزيادة الطول في الصيدلية: حقيقة وخيال
•
حقيقة وخيال حول حبوب لزيادة الطول في الصيدلية تعد زيادة الطول من الأمور التي تشغل بال الكثيرين، ولذلك يبحث العديد من الأشخاص عن وسائل لزيادة الطول بشكل سر…
-
فوائد المكملات الغذائية لصحة الجسم
•
مكمل غذائي تُعتبر المكملات الغذائية من أحد الوسائل الفعالة لتحسين صحة الجسم والحفاظ على سلامته. تحتوي هذه المكملات على مجموعة متنوعة من الفيتامينات والمعا…
-

مكمل غذائي لزيادة وزن الأطفال: دور الصيدلية في تحسين التغذية
•
مكمل غذائي لزيادة وزن الأطفال: دور الصيدلية في تحسين التغذية تعتبر مشكلة نقص الوزن لدى الأطفال أمرًا مقلقًا للكثير من الأهالي والمختصين في مجال الصحة، حيث…
-
فوائد وأضرار المكملات الغذائية: الحقيقة وراء الاستخدام الصحيح
•
المكملات الغذائية هي عناصر غذائية تستخدم لتكملة النظام الغذائي اليومي، وتعد مصدرا مهما للفيتامينات والمعادن التي يحتاجها الجسم. ومع انتشار استخدام المكملات…
-

أكثر منتج فعال لزيادة الطول يمكنك استخدامه الآن
•
أفضل منتج لزيادة الطول: يعتبر زيادة الطول من الأمور التي يبحث عنها الكثيرون، فالطول يعتبر عاملاً مهماً في تحسين الثقة بالنفس والمظهر العام. ومن هنا تأتي أه…
-

أفضل فيتامين للشعر والاظافر من الصيدلية
•
مقدمة عن دور فيتامين (هـ) في ترطيب وتغذية الشعر والأظافر: فيتامين (هـ)، المعروف أيضًا باسم الفيتامين E، هو مضاد أكسدة قوي يلعب دورًا حاسمًا في الحفاظ على صحة الشعر والأظافر. يعمل فيتامين (هـ) على ترطيب البشرة وتغذية الشعر والأظافر، مما يساعد على تحسين مظهرها وصحتها بشكل عام. توضيح لفوائد استخدام…
-

افضل فيتامين للشعر الخفيف
•
مقدمة عن دور فيتامين (بيوتين) في تعزيز نمو الشعر وتقويته: فيتامين بيوتين، المعروف أيضًا باسم فيتامين B7 أو فيتامين H، يعتبر أحد العناصر الغذائية الأساسية لصحة الشعر. يلعب البيوتين دورًا حاسمًا في تعزيز نمو الشعر وتقويته. إليك كيفية يعمل فيتامين البيوتين على تحقيق هذا الغرض: 1. تعزيز نمو الشعر: يعتبر…
-

أفضل فيتامين للشعر والبشرة
•
مقدمة عن دور فيتامين (هـ) في تحسين مظهر البشرة وترطيبها: فيتامين (هـ)، المعروف أيضًا باسم الـ “توكوفيرول”، يُعتبر مضاد أكسدة قويًا ويساعد في تعزيز صحة البشرة وتحسين مظهرها بشكل عام. إليك كيف يعمل فيتامين (هـ) على تحسين مظهر البشرة وترطيبها: 1. تقوية حاجز البشرة: يساعد فيتامين (هـ) في تقوية حاجز…
-

افضل فيتامينات الشعر والاظافر
•
فيتامين (ب)، المعروف أيضًا باسم الـ Complex B Vitamins، يُعتبر من العناصر الغذائية الأساسية التي تلعب دورًا حاسمًا في صحة الشعر والأظافر. يتألف فيتامين (ب) من مجموعة من الفيتامينات الفردية، مثل الثيامين (B1)، والريبوفلافين (B2)، والنياسين (B3)، والبيوتين (B7)، والبانتوثنيك أسيد (B5)، والبيريدوكسين (B6)، وغيرها. فوائد فيتامين (ب) للشعر والأظافر:…
-

أفضل فيتامينات لتطويل الشعر وتكثيفة بسرعة
•
تحقيق نمو الشعر الصحي والسريع يعتبر هدفًا مهمًا للعديد من الأشخاص، والتغذية السليمة تلعب دورًا أساسيًا في تحقيق هذا الهدف. الفيتامينات والمعادن هي عناصر غذائية أساسية لصحة الشعر، حيث تلعب دورًا حاسمًا في تعزيز نموه وتسريعه. دعونا نلقي نظرة على أهمية الفيتامينات في تعزيز نمو الشعر بسرعة، ثم نتحدث عن…
-
فيتامينات للشعر من الصيدلية
•
الفيتامين (أ)، المعروف أيضًا باسم الريتينول، يعتبر أحد العناصر الغذائية الأساسية التي تلعب دوراً مهماً في صحة الشعر. يعتبر الفيتامين (أ) مضاداً للأكسدة، وهو يساعد في تعزيز نمو الخلايا السليمة وتجديدها، مما يسهم في صحة الشعر وقوته. فوائد فيتامين (أ) للشعر تشمل: 1. تحفيز نمو الشعر: يساعد الفيتامين (أ) في…
-

حبوب التنحيف ماي ليزا مكوناتها وطريقة استخدامها
•
حبوب التنحيف ماي ليزا، مؤخراً، شهدنا ارتفاعاً ملحوظاً في معدلات البدانة والسمنة، حيث باتت نسبةٌ كبيرة من الناس تجد مشقةً في الوصول إلى القوام أو الوزن المثالي بسهولة، وهذا الأمر أدى إلى زيادة الإقبال على استعمال أقراص التخسيس والمستحضرات التي تُروّج كوسائلٍ معينةٍ في فقدان الوزن والتخلص من الدهون ومنها…
-

شاي الماتشا الاصلي فوائده وطريقة إستخدامه
•
شاي الماتشا الاصلي، لطالما كان شراب الماتشا حجر الأساس في مراسم الشاي اليابانية العريقة على مدى قرون، وقد اكتسب شهرة واسعة حول العالم ويُقدَّم بأساليب متنوعة مثل اللاتيه ويُستخدم كمكوِّن في الطهي في مجموعة واسعة من الأطباق، بدءًا من البوظة وحتى توابل السلطات، نظرًا لما يتمتع به من منافع صحية…
-

فوائد الماء للرجال المتزوجين
•
شرب الماء يلعب دورًا مهمًا في دعم صحة الجهاز الإنجابي والتناسلي للرجال المتزوجين. إليك كيف يؤثر الماء على جودة السائل المنوي وزيادة فرص الإخصاب: 1. تأثير الماء على جودة السائل المنوي: شرب كميات كافية من الماء يمكن أن يسهم في تحسين جودة السائل المنوي. السائل المنوي يحتوي على نسبة عالية…
-

فوائد شرب الماء على الريق
•
تنشيط الجسم باستهلاك الماء عند الاستيقاظ في الصباح يعتبر عادة مفيدة لعدة أسباب، ومنها: 1. تعويض فقدان السوائل: خلال فترة النوم، يمكن أن يفقد الجسم كميات معينة من الماء عن طريق التنفس والتعرق. بالتالي، يعتبر شرب الماء عند الاستيقاظ واحدة من أولى الخطوات لتعويض هذا الفقد وتجديد السوائل في الجسم.…
-

فوائد الماء في الحياة
•
بالتأكيد، يعد الماء أساسياً لبقاء الحياة على الكوكب، وهذا ينطبق على جميع الكائنات الحية بما في ذلك البشر، وذلك لعدة أسباب: 1. ضرورية للبقاء على قيد الحياة: الماء هو جزء لا يتجزأ من تكوين خلايا الكائنات الحية. يشكل الماء الجزء الأكبر من وزن الخلايا ويشارك في جميع العمليات الحيوية مثل…
-
فوائد شرب 3 لتر ماء يوميا
•
مع العناية المناسبة والتركيز على شرب كمية كافية من الماء، يمكن الحفاظ على الترطيب الجيد للجسم. إليك كيف يمكن تحقيق ذلك: 1. أهمية ترطيب الجسم بشكل كافٍ: – الترطيب الجيد للجسم أمر أساسي للحفاظ على صحة الجلد ووظائف الجسم بشكل عام. – يساعد الترطيب الجيد على منع الجفاف، والذي يمكن…
-

فوائد شرب الماء للبشرة
•
ترطيب البشرة له أهمية كبيرة للحفاظ على مظهرها الصحي والشاب، ويعتبر شرب الماء واحدًا من أفضل الطرق لترطيب البشرة من الداخل. دعني أوضح لك كيفية تأثير شرب الماء على ترطيب البشرة ومكافحة الجفاف: 1. تحسين ترطيب البشرة من الداخل: – عندما تكون الخلايا الجلدية مهيأة بمستويات كافية من الرطوبة، يكون…
-

فوائد شرب الماء للجنس
•
يعتبر شرب الماء أمرًا أساسيًا لصحة الجسم بشكل عام، ولكن له أيضًا تأثيرات إيجابية على صحة الجنس والقدرة الجنسية. فيما يلي توضيح لبعض فوائد شرب الماء لصحة الجنس وأهمية الاستهلاك اليومي للماء في دعم الصحة الجنسية: 1. تعزيز الدورة الدموية والصحة القلبية: – شرب كميات كافية من الماء يعزز الدورة…
-

فوائد المياه واضرارها للانسان
•
يُعتبر الماء عنصرًا أساسيًا للحياة، ويتمتع بأهمية كبيرة لصحة الإنسان. يلعب دورًا حاسمًا في تحقيق التوازن الهيدروليكي في الجسم ودعم وظائفه المختلفة. فيما يلي توضيح لأهمية الاستهلاك اليومي للماء: أهمية الاستهلاك اليومي للماء للحفاظ على صحة الجسم: 1. تحقيق الترطيب الجيد: يعتبر الماء وسيلة رئيسية لتحقيق الترطيب الجيد في الجسم،…
-

فوائد المياه للرجال والنساء
•
الماء هو عنصر أساسي للحياة، وله تأثيرات هامة على صحة الإنسان بشكل عام، سواء كان رجلاً أو امرأة. إليك بعض الفوائد الهامة للماء على الصحة العامة: 1. ترطيب الجسم: يعتبر الماء وسيلة أساسية لترطيب الجسم، حيث يساعد في الحفاظ على توازن السوائل داخل الجسم، وذلك يسهم في عمليات مثل التمثيل…
-

افضل مكمل غذائي لزيادة طول القامة والتركيز ارجيفيت فوكس
•
مع تزايد الوعي بأهمية الصحة والعناية بالجسم، أصبحت الرغبة في الوصول إلى القامة المثالية وتعزيز التركيز والأداء العقلي أمرًا مهمًا للكثيرين. ومن بين العوامل التي يسعى الكثيرون إلى تحقيقها هي زيادة الطول وتعزيز القدرة على التركيز. وفي هذا السياق، يشهد سوق المكملات الغذائية توافر مجموعة واسعة من المنتجات المصممة لتحقيق…
-

ارجيفيت فوكس شراب متعدد الفيتامينات لزيادة طول القامة
•
تعتبر فترة الطفولة والمراهقة من أهم المراحل التي يتم فيها تكوين القامة ونمو العظام بشكل طبيعي. ومن المعروف أن الغذاء والتغذية السليمة تلعب دورًا حاسمًا في تحقيق نمو وتطور صحيحين للطفل. وفي هذا السياق، يأتي دور مكملات الفيتامينات والمعادن لزيادة الطول، ومن بين هذه المكملات يبرز “أرجيفيت فوكس شراب متعدد…
-

شاي ماي ليزا للتنحيف وخسارة الوزن
•
مع التزايد المستمر في الوعي بأهمية الصحة واللياقة البدنية، يبحث العديد من الأشخاص عن طرق طبيعية وفعّالة لخسارة الوزن وتحسين جودة حياتهم. ومن بين الخيارات الشهيرة والمثيرة للاهتمام في هذا السياق يأتي شاي ماي ليزا للتنحيف وخسارة الوزن. يعتبر شاي ماي ليزا خيارًا شهيرًا بين الأشخاص الذين يسعون لتحسين توازنهم…
-

كبسولات ماي ليزا للتخسيس وخسارة الوزن الزائد
•
في عالم مليء بالخيارات والمنتجات التي تُعلن عن قدرتها على المساعدة في فقدان الوزن، تبرز كبسولات ماي ليزا كخيار شهير ومحبب للكثيرين السعيين للتخلص من الوزن الزائد. تعتبر هذه الكبسولات جزءًا من سوق المكملات الغذائية التي تتميز بتعدد الخيارات والوعود، ولكن يبقى استخدام كبسولات ماي ليزا محل اهتمام خاص لدى…
-

حبوب ماي ليزا للتنحيف وفقدان الوزن
•
في عالم يعج بالمعلومات والمنتجات التي تدعي فعالية في فقدان الوزن، يبحث الكثيرون عن الحلول الفعّالة التي تسهم في تحقيق أهدافهم الصحية بطريقة آمنة ومستدامة. ومن بين هذه الحلول، تبرز حبوب ماي ليزا كخيار شهير ومثير للاهتمام لمن يرغبون في خسارة الوزن وتحسين صحتهم بشكل عام. تقدم حبوب ماي ليزا…
-

أرجيفيت فوكس مكمل غذائي لزيادة طول القامة والتركيز
•
في عالم يسعى فيه الأفراد إلى تحقيق أقصى إمكانياتهم البدنية والعقلية، يبحث الكثيرون عن وسائل طبيعية وفعّالة لتعزيز طول القامة وتعزيز التركيز والأداء العقلي. تتنوع الطرق المتاحة لتحقيق هذه الأهداف، ومن بين الخيارات المبتكرة التي تلقت اهتمامًا متزايدًا تأتي استخدام مكملات غذائية مثل “أرجيفيت فوكس”. أرجيفيت فوكس هو مكمل غذائي…
-

حبوب ارجيفيت فوكس لزيادة الطول
•
تعتبر زيادة الطول من الأمور التي يهتم بها الكثيرون، سواء كانوا في مرحلة النمو خلال الطفولة والمراهقة، أو حتى البالغين الذين يسعون للحصول على قامة أطول. وفي سعيهم وراء تحقيق هذا الهدف، يلجأ البعض إلى استخدام المكملات الغذائية المصممة خصيصًا لدعم نمو الطول، مثل حبوب أرجيفيت فوكس. حبوب أرجيفيت فوكس…
-

حبوب ماي ليزا افضل حبوب التخسيس وتأثيراتها
•
في عالم مليء بالخيارات والمنتجات المختلفة لفقدان الوزن، يبحث الكثيرون عن الحلول الفعّالة والآمنة لتحقيق أهدافهم في التخسيس. من بين تلك الخيارات، تبرز حبوب ماي ليزا كواحدة من أفضل حبوب التخسيس المتوفرة في السوق. فهذه الحبوب تتميز بتركيبتها الفريدة وفعاليتها المثبتة في مساعدة الأفراد على خسارة الوزن بشكل طبيعي وصحي.…
-

عسل المالكي الماليزي وقيمته الغذائية
•
عسل ملكات النحل أو ما يعرف بـ عسل المالكي الماليزي، يقع ضمن أهم المنتجات الطبيعية، والتي يتم إنتاجها من خلال النحل الشاب، حيث تحتوي على كميات مرتفعة من البروتينات الضرورية للقيام يالأنشطة اليومية للأفراد، وهو عبارة عن مادة تشبه إلى حد كبير الحليب ينتجه نحل العسل لأسباب محددة لكونه الطعام…
-

أفضل كريم تفتيح البشرة وكيفية استخدامه
•
دون أدنى شك أن وجود البقع الداكنة واسمرار البشرة مشكلة مؤرقة للغاية، لذا يلجأ الكثيرين إلى كريم تفتيح البشرة والذي يقوم بالحد من انتاج صبغة الميلانين والتي تضفي على البشرة لون لحمايتها ضد الأضرار ومن بينها أشعة الشمس الحارقة، حيث يتنوع كريم تفتيح البشرة من الصيدلية ما بين الأنواع التي…
-

ما هى فوائد زيت العلق الاصلي واستخدامه للبشرة
•
في نطاق التطور اللافت الذي حظي به زيت العلق الاصلي الماليزي، فقد تم إعداده ليكون خيار أمثل للعديد من الأشخاص على مستوى العالم أجمع، حيث يقع ضمن أهم المنتجات الطبيعية المستخرجة من دودة العلق التي تعيش خلال دورة حياتها بالمياه العذبة بدولة ماليزيا، كما ينطوي زيت العلق الاصلي على العديد…
-

تعرف على أفضل فيتامينات و حبوب لزيادة طول القامة
•
يبحث الكثير من الأشخاص الذكور والإناث عن حبوب لزيادة طول القامة، حيث أن قصر القامة لدى البالغين تمثل مشكلة نفسية لهم وتؤثر على ثقتهم، وانتشر الكثير من الأدوية والفيتامينات لزيادة الطول يعمل كل منهم بشكل أساسي عن طريق تحفيز هرمون النمو مثل الكثير من حبوب هرمون النمو لزيادة الطول للبالغين،…
-

تعرف على فوائد ارجيفيت فوكس ومميزاته
•
تتنافس كبرى الشركات على إنتاج مكملات غذائية تلبي متطلبات الأشخاص، ويعتبر ارجيفيت فوكس أحد أفضل المكملات الغذائية الموجودة في الأسواق، يحتوي على تركيبة من العناصر المهمة للصحة الذهنية والبدنية، وينصح به الكثير من الأطباء، حيث يتم استخدامه بهدف زيادة طول القامة، وتعزيز الذاكرة والتركيز، حقق ارجيفيت فوكس نتائج ممتازة في…
-

افضل فيتامينات تساقط الشعر
•
عند البحث عن فيتامينات لتساقط الشعر، يمكن أن تكون الخيارات متعددة ومختلفة. ومع ذلك، هناك بعض الفيتامينات الرئيسية التي يمكن أن تكون مفيدة في تعزيز نمو الشعر ومكافحة التساقط. إليك بعض الفيتامينات الشائعة التي يُعتقد أنها مفيدة: 1. يتامين ب (بيوتين): يُعتبر البيوتين واحدًا من الفيتامينات الأساسية لصحة الشعر. يساهم…
-

تجربتي مع فيتامين بيوتي جاميز
•
تجربتي مع فيتامين بيوتي جاميز كانت فعلاً تجربة مميزة وتحولت إلى جزء أساسي من روتيني اليومي. من البداية، كنت أبحث عن طريقة لتحسين صحة بشرتي وشعري بشكل طبيعي وفعال، وعندما سمعت عن فيتامين بيوتي جاميز، قررت إعطائه فرصة. بعد استخدامه لبضعة أسابيع، لاحظت تحسناً ملحوظاً في مظهر بشرتي وصحة شعري.…
-

افضل فيتامينات للرجال لزيادة الانتصاب
•
مفهوم الصحة الجنسية للرجال يشمل مجموعة من الجوانب الصحية والنفسية التي تؤثر على قدرة الرجل على الاستمتاع بحياته الجنسية بشكل صحي ومريح. واحدة من أهم هذه الجوانب هي القدرة على الانتصاب بشكل صحي وقوي. يعتبر الانتصاب عملية فيزيولوجية تتطلب تدفق الدم بقوة إلى الأعضاء التناسلية، ويتأثر بها عدة عوامل منها…
-

شوقر بير هير
•
شوقر بير هير هو منتج طبيعي يستخدم لتحسين صحة الشعر وتعزيز نموه. يشتمل هذا المنتج عادة على مكونات طبيعية مثل الفيتامينات والمعادن والمكونات النباتية التي تعتبر مفيدة للشعر. ويمكن أن تشمل تلك المكونات بيوتين، وزيوت الأوميغا-3، وفيتامينات أخرى مثل فيتامين C وفيتامين D. من فوائد شوقر بير هير لصحة الشعر:…
-

أفضل حبوب فيتامين للشعر والبشرة والأظافر
•
نعم، صحيح أن فيتامين A يتمتع بعدة فوائد لصحة الشعر وجمال البشرة وقوة الأظافر، وهذه بعض الفوائد الرئيسية: 1. تعزيز صحة فروة الرأس: يُعتبر فيتامين A أساسيًا لإنتاج الزيوت الطبيعية في فروة الرأس، وهذا يساعد في ترطيب الشعر ومنع جفاف الفروة وتهيجها، مما يعزز نمو الشعر الصحي. 2. تحسين مظهر…